TL;DR
HiDream-O1-Image(2026-05 リリース、OpenWeight 8B、Artificial Analysis Text-to-Image Arena 8 位の T2I モデル)の skeleton (= 試着) モードで「ポーズが言うこと聞かない」現象を 8 パターン + layout 3 パターンで実証ベンチした結果、3 つの反直感的事実が見えた。
- openpose ref を渡すと、かえってポーズが ref の構図に固着する。動的なポーズが欲しい時は openpose ref を抜いて prompt 経由で指示する方が強い
- ref を 6 枚(face+bg+pose+parts のフルセット)にすると個別 ref の解像度が 768px に落ちて細部が崩れる。3-4 枚で 1024px に保つほうが品質高い
- README 推奨の
shift=1.0は試着用途専門。ポーズ・服装入替ならshift=2.0-2.5、シーン丸ごと作り変えならshift=3.0
pipeline.py を読むと「skeleton モードに専用処理がない」ことが分かる。/generate/skeleton も /generate/ip も内部では完全に同じ multi-ref 経路を通っており、ref が「顔/背景/openpose/衣装」のどれかはプロンプトでしか伝わらない。これが現象の根本原因。
動機
HiDream-O1-Image をローカル GPU (RTX PRO 6000 Blackwell, 96 GB) で常駐させて自前プラットフォームに統合したところ、skeleton (試着) モードがプロンプト指示に追従しない問題に遭遇した。「両手を上げてジャンプして」と書いても、棒立ちの試着写真しか出てこない。
ガードレール(NSFW 検閲とか、安全ポリシー)かと思って safety|nsfw|guard|filter|moderate|censor で grep したが、HiDream の codebase にはそういった機構は一切なかった(CSS の backdrop-filter: blur のみヒット)。MIT ライセンスの OpenWeight 通り、検閲フリー。
じゃあ何が悪いのか。pipeline.py を読み込みつつ、8 + 3 パターンを実機で叩いた結果が以下。
環境
- GPU: NVIDIA RTX PRO 6000 Blackwell Max-Q (96 GB VRAM)
- PyTorch: 2.12.0 + CUDA 13.0
- flash-attn: 2.8.3 (sm_120 限定ビルド)
- モデル: HiDream-O1-Image Full (8B, bf16, ~16.4 GiB resident)
- 推論サーバー: 自前 Python BaseHTTPRequestHandler 常駐 (port 8895)
- 解像度: pipeline 内部バケットで強制 2048×2048 にスナップ
50 ステップ生成 1 枚あたりの実測:
| モード | 時間 | iter speed |
|---|---|---|
| t2i (ref なし) | ~33s | 1.52 it/s |
| edit (1 ref) | ~76s | 1.01 it/s |
| skeleton (multi ref) | ~84s | 1.34 it/s |
| ip (multi ref) | ~76s | 1.81 it/s |
| layout (multi ref + bbox) | ~83s | 1.21 it/s |
検証素材
HiDream リポジトリの assets/IP_skeleton/ にスケルトン用フルセットが入っている。これを元素材に使う。
| ref | 内容 | 用途想定 |
|---|---|---|
 | 人物の顔写真 | アイデンティティ参照 |
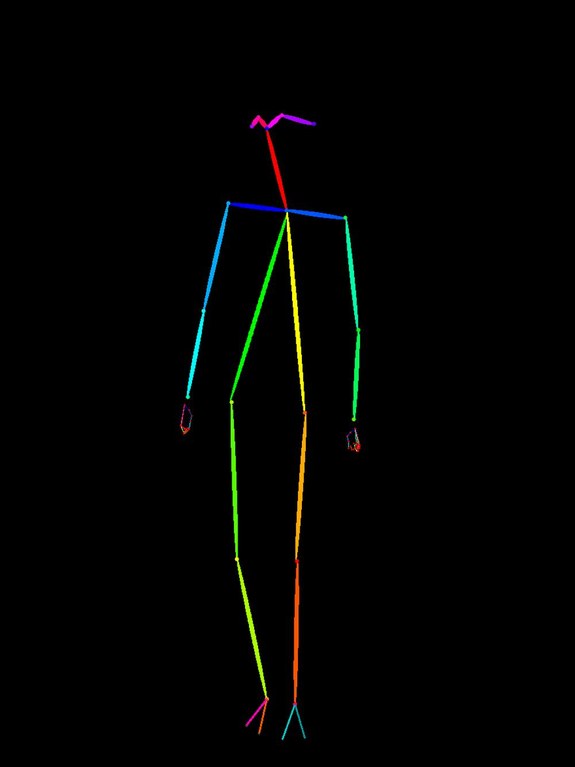 | OpenPose 形式の棒人間 | ポーズ指定 |
 | 背景写真(インテリア) | シーン参照 |
  | 衣装パーツ(セーター、ブーツ) | 服装参照 |
8 パターン skeleton ベンチ
各パターンで /api/studio/skeleton (= HiDream の generate_image() を skeleton モード相当の引数で呼ぶ) を叩いている。shift と guidance_scale 以外のパラメータは固定 (50 steps, seed=42)。
A — ベースライン(README デフォ、6 refs フル投入)
curl -X POST http://localhost:8895/generate/skeleton \
-H 'Content-Type: application/json' \
-d '{
"prompt": "Create a realistic try-on image of the person wearing the provided clothing.",
"ref_image_paths": ["face","bg","openpose","part_1","part_2","part_3"],
"shift": 1.0, "seed": 42
}'

結果: 元の bg ref の壁・棚が完全再現されている。ポーズも openpose ref の通り棒立ち。試着としては忠実だが「動き」「自由度」は皆無。
B — shift 上げ(同 6 refs、shift=2.5)
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "Create a realistic try-on image of the person wearing the provided clothing.",
"ref_image_paths": ["face","bg","openpose","part_1","part_2","part_3"],
"shift": 2.5, "seed": 42
}'

結果: 棚が薄れた、人物のデザインが微変化。背景は依然 bg ref に固着。shift 上げるだけでは bg ref の引きを完全には外せない。
C — guidance も上げる(shift=2.5, guidance=7.0)
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "...",
"ref_image_paths": [...6 refs...],
"shift": 2.5, "guidance_scale": 7.0, "seed": 42
}'

結果: ネックレスが奇妙な形に変形。guidance 上げると artifacts が出始める。Full モデルの sweet spot は 5.0、7.0 は過剰。
D — ref を 3 枚に絞る(face + openpose + sweater)+ 具体プロンプト
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "A young Asian woman wearing a gray oversized sweater dress, standing in a relaxed pose, full body shot, soft natural lighting, white studio background.",
"ref_image_paths": ["face","openpose","part_1"],
"shift": 2.0, "seed": 42
}'

結果: 大改善。背景が真っ白スタジオに、衣装維持、ポーズも自然。bg ref を抜いた効果が大きい。これが「正しい試着」の出力。
E — 4 refs + ref 番号明示プロンプト
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "Full body try-on photograph. Subject: the woman from image 1. Pose: identical to the skeleton in image 2. Wearing: the gray oversized knit sweater dress shown in image 3, brown leather ankle boots shown in image 4. Studio lighting, plain background.",
"ref_image_paths": ["face","openpose","part_1","part_2"],
"shift": 2.0, "seed": 42
}'

結果: D と同等品質、boots も反映(やや控えめ)。ref 番号明示は効果ありだが、決定的差ではない。
F — openpose を抜いて prompt でポーズ指定
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "Full body photograph of the woman wearing the gray sweater dress and brown ankle boots, dynamic dancing pose with both arms raised above her head, joyful expression, photo studio with white seamless background, professional lighting.",
"ref_image_paths": ["face","part_1","part_2"],
"shift": 2.5, "seed": 42
}'

結果: 🏆 両手挙げジャンプ完全成功。openpose ref 無し + prompt の動的指示で初めて動きが生成された。openpose ref を入れると prompt が負けることがここで確定する。
G — face 1 枚のみ + 自由 prompt(衣装も完全切替)
/generate/skeleton は最低 2 refs バリデーションがあるので /generate/ip 経由:
curl -X POST http://localhost:8895/generate/ip -d '{
"prompt": "Elegant full-body portrait of the woman wearing a vibrant red sequined evening gown with a thigh-high slit, standing confidently with one hand on her hip, soft cinematic lighting, dark blurred background.",
"ref_image_paths": ["face"],
"shift": 3.0, "seed": 42
}'

結果: 🏆 赤いセクシードレス完全生成。顔の同一性は維持、それ以外はすべてフリー。face 1 枚 + shift 3.0 が最大自由度パターン。
H — E と同設定で seed=999(ばらつき確認)
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "Full body try-on photograph. ...",
"ref_image_paths": ["face","openpose","part_1","part_2"],
"shift": 2.0, "seed": 999
}'

結果: E と微差、boots がよりブラウン明確に。seed 振りは細部最適化に効くので、本番では 3-5 seed 振って best of N が定石。
レイアウトモードも見ておく(おまけ 3 パターン)
layout_bboxes で「複数被写体を画像内のどの位置に配置するか」を相対座標 [x1, x2, y1, y2] で指定できる、ということになっている。実際の挙動を確認した。
入力 ref は 2 人分の顔写真(女性、男性):


L1 — 横並び(女性 left, 男性 right)
"layout_bboxes": "[[0.0,0.5,0.1,0.95],[0.5,1.0,0.1,0.95]]"

結果: 左右が入れ替わった(男性 left, 女性 right)。ref 順序と bbox 順序の対応は保証されない。
L2 — 上下分割(女性 top, 男性 bottom)
"layout_bboxes": "[[0.2,0.8,0.0,0.5],[0.2,0.8,0.5,1.0]]"

結果: 女性が奥、男性が手前のレイヤー構図に。「上下」ではなく「奥行き」として解釈された。
L3 — 大小(女性 大、男性 小)
"layout_bboxes": "[[0.1,0.65,0.1,0.95],[0.7,0.97,0.05,0.45]]"

結果: 両者ほぼ同サイズで横並び。bbox のサイズ指定は効かない。
→ Layout モードは 「集合写真生成のヒント」 として捉えるのが正しい。Photoshop の精密配置ではない。複数被写体を 1 枚にする時の構図ヒント止まり、座標精度は期待しない。
なぜそうなるか — pipeline.py を読む
HiDream の挙動を支配するのは models/pipeline.py の generate_image() 関数。読んで分かった 3 つの構造的事情:
1. ref 数が増えると個別解像度が落ちる
pipeline.py:198-202:
if K == 1: max_size = max(height, width) # 2048
elif K == 2: max_size = max(height, width) * 48 // 64 # 1536
elif K <= 4: max_size = max(height, width) // 2 # 1024
elif K <= 8: max_size = max(height, width) * 24 // 64 # 768
else: max_size = max(height, width) // 4 # 512
6 枚 ref を投入すると各 ref が 768px に圧縮される。openpose の細い線、衣装の細かい模様、顔の表情が一気に潰れる。3-4 枚に絞ると 1024px に保たれて細部が立つ。
2. skeleton モードに専用処理が無い
pipeline.py:178-275 を見ると、skeleton 用の特別な分岐は存在しない。/generate/skeleton も /generate/ip も内部では完全に同じ multi-ref 経路を通る:
content = [{"type": "image"} for _ in range(K)]
content.append({"type": "text", "text": caption})
messages = [{"role": "user", "content": content}]
「これは顔」「これは openpose」「これは衣装パーツ」という role hint はモデルに渡らない。すべて「ただの参照画像 K 枚」として並列に処理される。役割を伝えたければ prompt のテキストで明示するしかない。
これが「openpose ref より prompt の方が強い」現象の正体。openpose ref はあくまで「画像のどこかにこんな線画がある参照」として処理され、ポーズ指定子としての役割は明示的に伝わらない。一方 prompt の dynamic dancing pose with both arms raised は明示的な動詞・名詞として語彙レベルで処理される。
3. shift パラメータの効き
shift は scheduler の noise schedule 強度を調整する。値の体感:
- 1.0 = ref 構図に最大忠実、自由度ゼロ → 試着用途専門
- 2.0-2.5 = 実用域、ref からの逸脱を許容
- 3.0+ = ほぼ自由生成、ref はアイデンティティ参照のみ
README が IP/Skeleton/Layout で 1.0 を推奨してるのは「典型的な試着・キャラ一貫」を想定したもの。「ポーズ切替」「衣装入替」「シーン作成」みたいに ref と異なる構図を作りたいなら 2.0 以上が必須。
用途別ベストプラクティス(実証済みまとめ)
| やりたいこと | endpoint | refs | shift | 備考 |
|---|---|---|---|---|
| 元シーン忠実な試着 | /skeleton | 6 (face+bg+pose+3parts) | 1.0 | README デフォ。ref 全部に強く忠実 |
| 服装維持 + 自然な立ち姿 | /skeleton | 3-4 (face+衣装、bg/pose 抜き) | 2.0 | bg ref を抜くと白スタジオ化、ref 数減で各 ref 解像度 768→1024 |
| ポーズ大胆切替 | /skeleton | 3 (openpose 抜き) | 2.5 | openpose ref より prompt の方が動きを支配する |
| 服装も完全切替 | /ip | 1 (face のみ) | 3.0 | 最大自由度、顔だけ維持。skeleton モードは最低 2 refs バリデーションで弾かれる |
| 集合写真 | /layout | 複数人 ref + 大雑把な bbox | 1.0 | bbox はざっくり構図ヒント、サイズ階層は効かない、ref 順 ↔ bbox 順保証なし |
| 細部最適化 | 同設定 | 同 | 同 | seed を 3-5 振って best of N |
まとめ
HiDream-O1-Image の skeleton モードを「試着シミュレータ」だと思って使うと、ガードレールでもないのに「言うこと聞かない」という体感になる。原因はモデルやポリシーではなく、pipeline の構造的事情(ref 数で解像度落ちる + skeleton 専用処理がない + shift が ref 引っ張り力)にある。
実用的な落とし所:
- 試着 = 6 refs full + shift 1.0(README デフォ通り)
- 動きを変えたい = openpose ref 抜く + prompt で動詞指定 + shift 2.5
- 完全自由なシーン作り = face 1 枚 + shift 3.0 +
/ip経由
Layout モードも「精密 bbox」ではなく「集合写真ヒント」として理解すれば期待値ズレない。
ベンチに使った素材・コマンドは HiDream-O1-Image リポジトリ の assets/IP_skeleton/ assets/IP_layout/ をそのまま使えるので再現可能。shift と ref 数を変えるだけで挙動が大きく変わる遊び場として、試行錯誤しながら手応えを掴むのが早い。
追記: openpose ref を変えてみた — 「prompt が常に強い」は条件付きだった
公開後、「違う形状の openpose を入れたらどうなるか」を追加検証したら、上の結論を修正する必要があると分かった。
加工した openpose を ref に入れる(4 パターン)
元の openpose 画像 (0.openpose.jpg、立ち姿) を上下反転・90 度回転して「不自然なポーズ」に加工し、prompt は普通の立ち姿を指定して挙動を観察した。
| 加工 | 画像 |
|---|---|
| 上下反転 (逆立ち) | 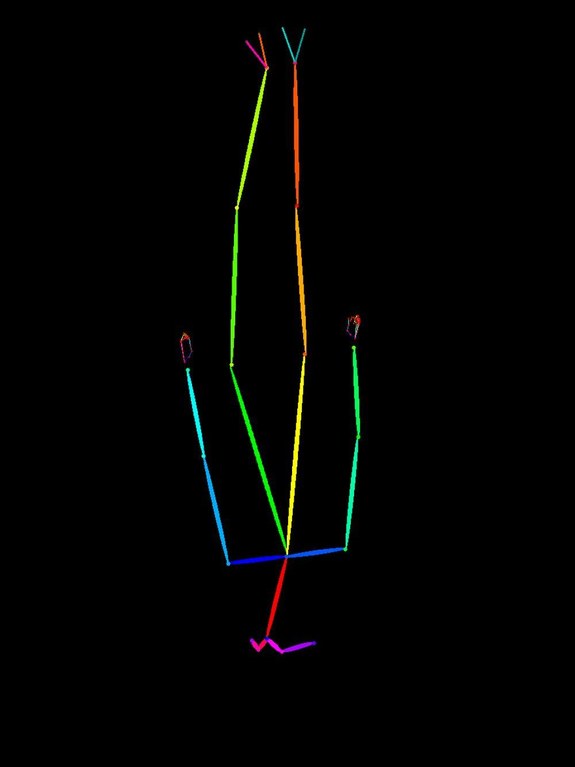 |
| 90 度回転 (横臥) |  |
| Test | openpose ref | prompt | 結果 |
|---|---|---|---|
| O1 baseline | 元 (立ち姿) | 立ち姿 |  期待通り立ち姿 期待通り立ち姿 |
| O2 | 🙃 上下反転 | 立ち姿 |  立ち姿 (openpose 完全無視、prompt 勝ち) 立ち姿 (openpose 完全無視、prompt 勝ち) |
| O3 | 🙃 上下反転 | ジャンプ |  両手挙げジャンプ (openpose 無視、prompt 勝ち) 両手挙げジャンプ (openpose 無視、prompt 勝ち) |
| O4 | ↻ 90 度回転 | 立ち姿 |  立ち姿だがキャンバス自体が 90 度回転! 立ち姿だがキャンバス自体が 90 度回転! |
ここまでは「不自然な ref はモデルが棄却して prompt に倒す」「ただし大局的な構図方向 (縦長 vs 横長) は ref が影響する」という追加の発見だった。
しかし dramatic な ref + ポーズ無指定 prompt なら、ref が完全勝利した
HiDream の T2I で「カラフルな解剖学スケルトン、両腕 T 字に広げ、片脚を高く上げて木のヨガポーズ」を生成して ref として投入:
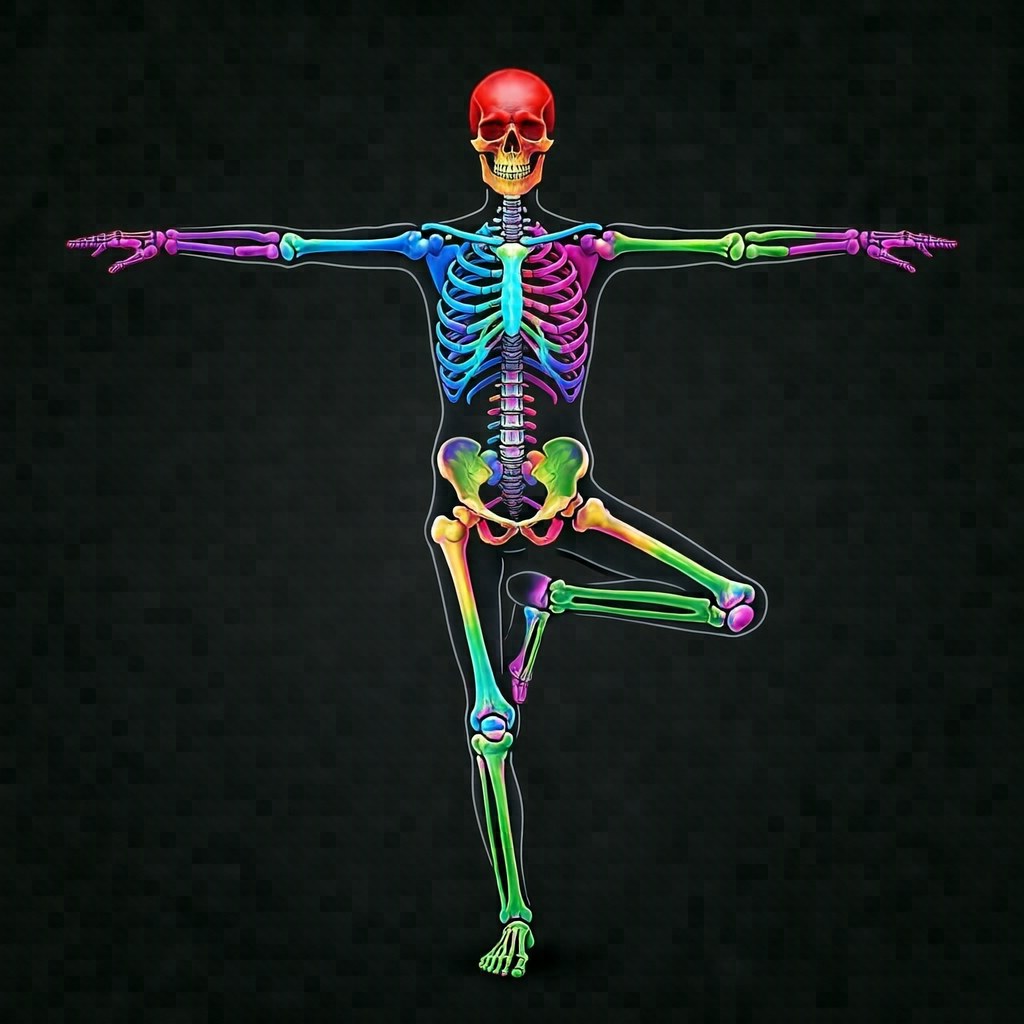
prompt はポーズ言及一切なし、被写体と衣装のみ:
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "Full body photograph of a young Asian woman wearing a gray sweater dress, soft natural lighting, white studio background.",
"ref_image_paths": ["face","SYNTHETIC_WARRIOR_SKELETON","sweater"],
"shift": 1.0, "seed": 42
}'
結果:

完全な木のヨガポーズが再現された — 両腕 T 字 + 片脚立ち、まさに ref のスケルトンそのまま。
修正した結論 (3 ルール)
ここまでの全 12 パターンを総合すると、HiDream の挙動は実はこう動いていた:
- prompt がポーズに言及してたら、それが第一優先 — ref と矛盾しても prompt が勝つ
- prompt にポーズ言及がない場合、ref のポーズが採用される — dramatic な ref ほど効きが明確
- ref が「不自然」(逆立ち skeleton 等) と判断されたら、モデルがデフォルト姿勢に倒す — ただし大局的な構図方向は反映されることがある
つまり「openpose ref は実質効いていない」というのは言い過ぎで、正しくは「prompt がポーズを語る場面では ref が上書きされる」が正確。本記事の 8 パターンは「prompt が動的なポーズを指定するシナリオ」だったので、結果的に「openpose ref は無力」に見えていた。
実用への影響
- ポーズを完全制御したい時: prompt にポーズを書かない + dramatic な openpose / skeleton ref を入れる → ref のポーズが転送される
- prompt で動きを指示したい時: openpose ref は外しても良い (ref を入れても prompt に上書きされる)
- ref と prompt が矛盾する時: prompt が勝つ (ref を入れても無駄)
要は「ポーズの出所をどっちに寄せるか」を prompt で言及するかしないか で切り替えられる。openpose ref を使いたければ「ポーズを prompt に書かない」のがコツ。
関連:
- HiDream-O1-Image: https://huggingface.co/HiDream-ai/HiDream-O1-Image
- リポジトリ: https://github.com/HiDream-ai/HiDream-O1-Image
- 自前実装の
/studio経路(Python image_server + Rust handler + Next.js UI)の設計記事は別途