Kotonia Articles
記事一覧
Kotonia の音声AI、AIチャット、画像生成、チーム共有に関する実装記録と製品アップデート。
 最新記事
最新記事顔と手足を持った AI 相棒 Iris を 1 日で組んだ — kotonia-desktop ローンチ
Tauri 2 + Ditto リップシンク + 音声合成で、声で頼むと自分の PC の bash を叩いて結果を喋り返してくる desktop アプリ Iris を 1 日で組んだ話。Claude Code 級の脳味噌に顔と声を載せ、月 ¥500 級のサブスクで実質無制限に動かす、ちょっと卑怯なハイブリッド構造。
#agent#tauri#voice
Unified VL 画像生成における T2I LoRA の編集経路への自動転移 — HiDream-O1 上の対照評価
HiDream-O1-Image 上で T2I 単独学習の LoRA アダプタが Image-to-Image 編集経路でも有意に機能するかを 5 軸 × 16 prompt × 5 LoRA 構成 × 3 参照画像 = 240 サンプルで対照評価。Unified VL アーキ固有の構造的性質と業界傾向、個人実装者への含意を整理。
#hidream#lora#image-generation
電車のスマホから自宅 GPU の AI エージェントにコードを書かせる週末 — Web ↔ kotonia-cli daemon を WebSocket で繋いだ話
自宅 PC に常駐させた kotonia-cli daemon を、kotonia.ai の Web 画面と WebSocket で双方向に繋いだ。外出先のスマホから「あのバグ直して」が打てて、家の RTX 6000 Blackwell が動き、worktree がリアルタイムでブラウザに流れてくる。device-code login、sync ApprovalHandler を async WS に橋渡しする話、マルチターン session の SessionRegistry まで、1 週末の設計と実装の細部。
#agent#websocket#rust
Specialized LoRA を作ろうとして「合法な NSFW dataset は構造的に存在しない」事実に遭遇した話 — 3-stage Caption で under-fit 天井を破った夜
v1 nipple LoRA の @1.5 > @1.0 という under-fit signal を出発点に、CSAM 汚染 + DRM で閉じた NSFW dataset 経路を構造分析、CivitAI RED + 3-stage Caption + informational value frame で V2 LoRA を訓練し、prompt adherence 大幅改善 + 汎化保持を A/B 確定するまでの一晩の研究記録。
#LoRA#image-generation#HiDream
AIに「技術記事を書くな」と言われたので、最後にその顛末を技術記事にする
Claude Fable 5 に自分のプロダクトと戦略を敵対的にレビューさせたら、技術の穴ではなく経営の穴を 4 つ突かれた。ソロ開発者が AI を経営会議の相手にする再現手順と、Opus 系では起きなかったことの記録。
#AI#Claude#個人開発
アバターチャットの感情情報量に天井がある問題と、70 年代心理学で moat を作った話
音声アバターは初回 wow が強い割に 2-3 ターンで「画面の情報量が収束する」段階に入る。リップシンクの帯域 ≠ 感情の帯域、という認識から出発して、LLM コンテキストを増やさず表情を N × M に伸ばす非対称設計に着地した記録。Ekman の FACS を借りる理由、フロンティアラボがこれを作らない理由、indie の moat としての射程まで。
#avatar-chat#ux#個人開発
ターミナルで完結する creative agent を 1 日で作った話 — 視覚優位ツールに殴られ続けてきた言語優位プレイヤーへ
kotonia-cli を 1 日で書き上げた記録。bash 1 ツール + 3 秒で届く画像生成 + ffmpeg ネイティブが、Claude Code / Codex が誰も埋めなかったカテゴリ空白を埋める。1 人開発がフロンティア API 屋に勝てる唯一の領域は、能力ではなく言語優位ユーザーへのロスレス UX だった。
#agent#cli#個人開発
16 コアが久しぶりに全力で唸った日 — DDR5 高騰の中、自宅で『準フロンティア OW』を動かす MoE 時代の CPU+RAM 復権
DeepSeek-V4-Flash (284B MoE / 13B active) を自宅の RTX 6000 + 128GB RAM で動かしてみたら、フル GPU と CPU offload の速度差が 2 倍しかなかった。RTX PRO 6000 みたいなごつい GPU を買わなくても準フロンティア OW を手元で動かせる時代になっていた、という記録。ただし 2026 年の DDR5 高騰で『メモリだけで GPU 級の支出』になる現実も併せて。
#llm#moe#deepseek
個人開発者の累積資産が初めて「複利」で立ち上がった日 — memory と git が agent 経由で「使われる側」に立った話
memory ファイルと git history を agent に semantic 圧縮させて新規記事の卵を機械的に発掘する pipeline を 1 セッションで構築。「個人開発者の累積資産が複利として立つ」条件を 3 つに整理した実装記録。
#ai#llm#agent
HiDream-O1-ImageのLoRAを自作した理由——包み隠さない版
HiDream-O1-Image向け汎用アニメ/セミリアル質感改善LoRAを作った動機、191枚の手動データ収集、NSFWコンバージョン戦略、そしてnoindex記事がユニーク閲覧1位だった話。技術詳細の日本語版。
#lora#hidream#imagegen
離脱率と戦う:個人開発で「地味なFix」に全振りした話
派手な新機能より、静かにコンバージョンを殺す摩擦を潰す。意図を保持する認証、登録後の自動ログイン、UIの嘘をなくす——個人BtoCの導線改善の記録と、その先にある本当のボトルネック。
#個人開発#ux#プロダクト
「大手が降りた動画領域」を個人で実験した記録 — モデル比較から I2V 主力化まで
セーフガードを外した自由な創作にニッチ需要はあるのか。個人開発でローカル GPU 一枚、モデル A/B から高解像度 I2V を主力に据えるまでの試行錯誤。
#個人開発#生成AI#動画生成
1 行アイデアを 40 秒コメディ動画にする 10-beat パイプライン
ローカル GPU で AI 動画コメディを量産したい開発者向け。1 行のアイデアから LTX-2 + HiDream + Gemma 4 で 40 秒の縦長動画 (Hook + 字幕付き) を 25 分で生成する 10-beat パイプラインの設計、罠、コード構造を記録。
#ai#動画生成#ffmpeg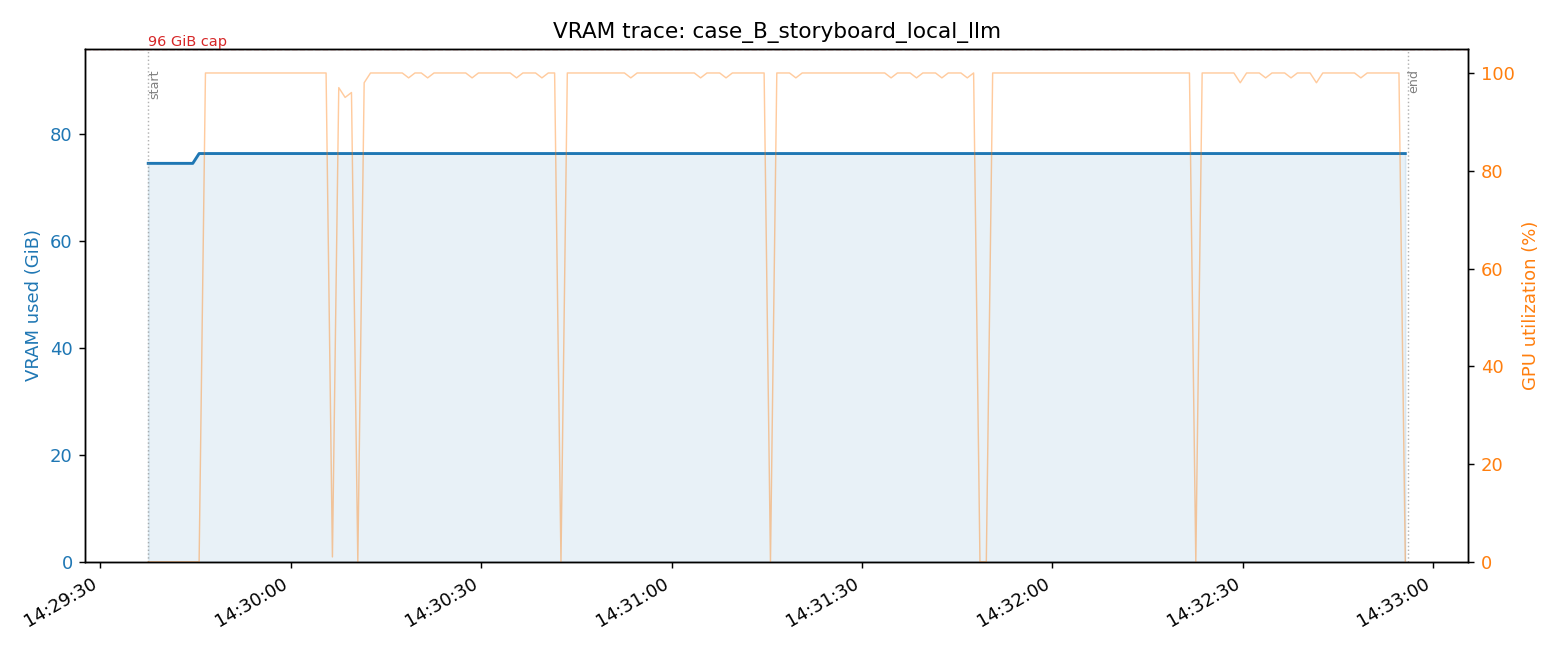
3万円のChromebookから、96GBのGPUへ ― 5年越しに諦めなかった話
AIをやりたくても非力なマシンしかなかった5年。Colabでお茶を濁し、震える指でRTX PRO 6000 Blackwell(96GB)を買うまでの、個人開発者の記録。
#個人開発#GPU#AI
メスガキ英会話で検索上位を取って、そして失った話
個人開発の niche AI 英会話「メスガキ英語学習」がなぜ刺さったか、検索1・2位を取った戦略、そして自前の原本がZennに奪われた顛末。
#個人開発#AI英会話#SEO
Zennにcanonicalを書いたつもりだったが、実際には効いていなかった話
個人開発サービスの登録数が落ちたので流入とcanonicalを調べ直したら、Zennへの全文クロスポスト運用に穴が見つかった記録。
#SEO#個人開発#Zenn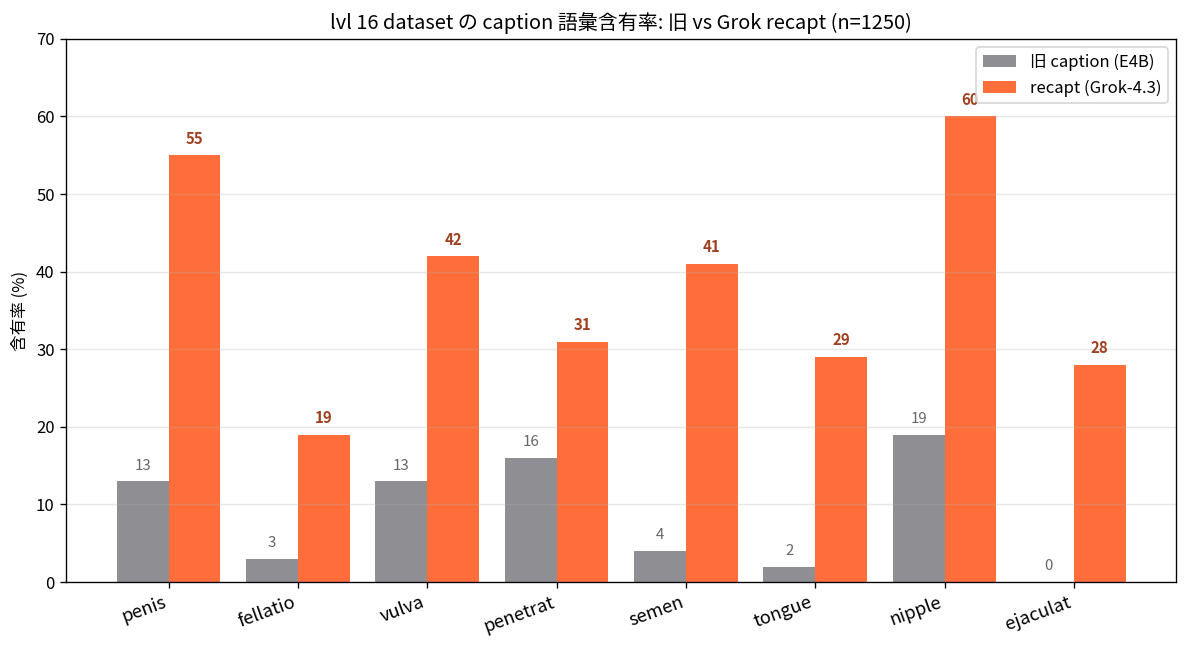
真因は層じゃなく語彙だった: HiDream-O1 の隠れた表現力を語彙修復で解禁する
HiDream-O1 (8B) の NSFW 表現力を解禁する過程で、真因が VLM キャプション生成器の言い換え (E4B が "fellatio" を "oral sex" に丸める) だったことを実証。Grok-4.3 + 2 段階プロンプトで語彙修復し、bitsandbytes 8-bit Adam で 96 GB GPU 単体で 8B 全層ファインチューン。同モデル + 異キャプションで描画の有無が分離する決定打を含む研究記録。
#HiDream-O1#fine-tuning#captioning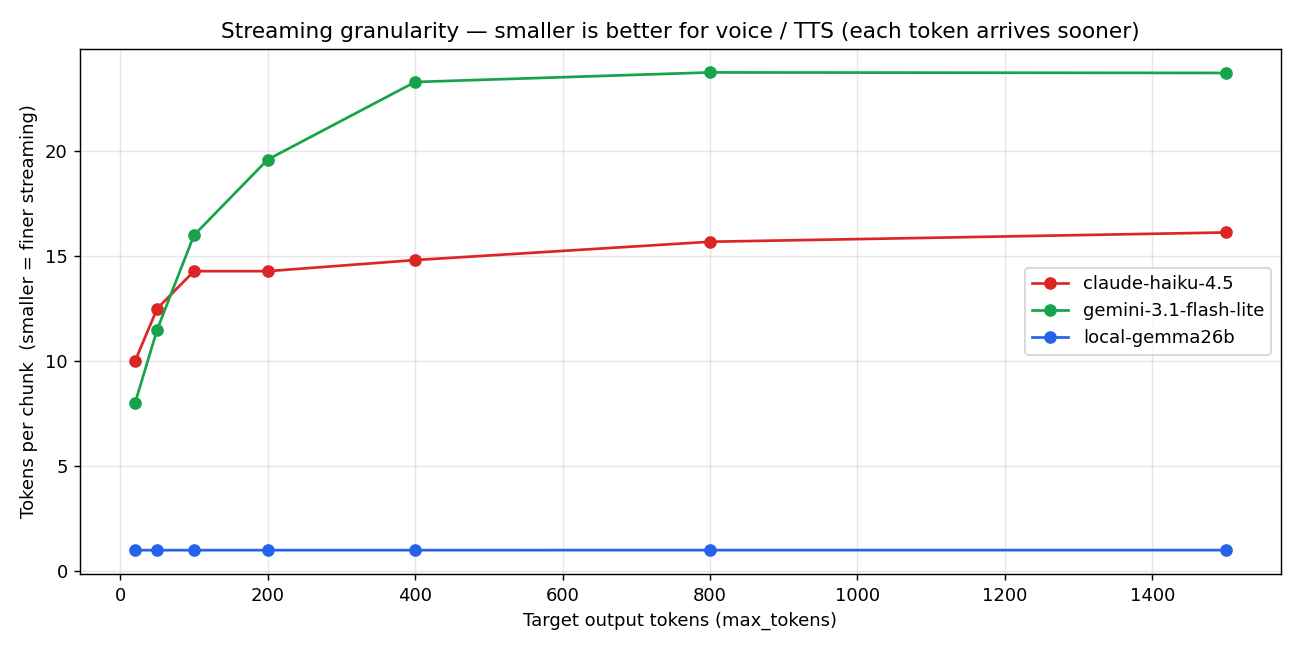
短文 LLM レイテンシを 600ms → 22ms に。高品質アバターが 1 秒以内に返事する voice-first を作るためにフロンティア API を捨てた、パフォーマンスチューニング狂の俺の理由のすべて
voice-first を本気で名乗るには 700ms TTFB を許容できない。Gemma 4 26B A4B Uncensored をローカル GPU に乗せて、API 課金ゼロ・TTFB 30x・uncensored を同時に達成した話。ベンチ 105 サンプルとグラフ 4 枚、stress test、実装差分、競合不可能な堀の整理まで。
#voice-first#local-llm#gemma-4
LTX-2.3 を 96GB GPU 1 枚で TTS と同居させる cold-start 構成
音声ロールプレイ製品に LTX-2.3 を組み込む際、persistent モードでは 86 GiB を VRAM に置きっぱなしになり TTS/Ditto と同居できない。cold-start に切り替えて idle 0 GiB / peak 40 GiB を達成した実装記録。
#ltx2#vram#cold-start
agent の self-discipline は信用するな — mining v2 で REJECT rule 3 件すり抜けの実例 → tool 層 blocking で構造的に治した話
prompt に「REJECT せよ」と書いた rule を、agent が 3 件すり抜けた実例。原因と tool 層に TF-IDF 重複検出を焼き込んで構造的に治した話。agent 設計の enforcement 原則。
#ai#llm#agent
HiDream のぽん出し → Dev に逃げる → VRAM が破綻 → プロンプトで殴って勝った話
HiDream-O1-Image のぽん出しが日本語プロンプトで崩壊する問題を、Dev-2604 への乗り換え検討 → VRAM 制約で破綻 → プロンプトエンハンサーで解決した実装記録。HiDream 特有の罠 4 つ (ブランド名焼き込み / cute で幼児体型 / Wong Kar-wai で韓国字幕 / idol-class で自動キャプション) を A/B bench で発見。
#hidream#diffusion#promptengineering
LTX-2 22B を fp8_cast で peak VRAM 40% 削減した話 — optimum-quanto は罠だった
LTX-2.3 22B の量子化を試した記録。optimum-quanto は LTX-2 transformer と互換性問題で動かず、LTX-2 native の `QuantizationPolicy.fp8_cast()` に切り替えて peak VRAM を 40 GiB → 24 GiB(cold-start, 768×512)に圧縮。3 解像度のベンチマークと cold-start / persistent の使い分け判断まで。
#ltx2#quantization#fp8
voice-first を名乗るなら『録音開始』ボタンを画面中央に置くな
voice-first を謳う AI キャラチャットの底に巨大マイクボタンが鎮座してたのは構造的な自己矛盾だった。モバイル CSS バグ報告から始まった調査が、製品コンセプトと UI の整合性チェックに発展した話。
#UX#個人開発#モバイル
HiDream skeleton: openpose ref より prompt が強い (実証 8 パターン)
HiDream-O1-Image (8B Full) の skeleton モードを 8 パターン + layout 3 パターンで実証ベンチ。openpose ref を渡すとかえってポーズが固着し、prompt 経由の指定が強い理由を pipeline.py を読み解いて解説。
#hidream#diffusion#openpose
個人開発で機能はあるのに使われてない問題、UI 分割で解いた
動画生成経由で登録した新規ユーザーが初日に離脱する問題を行動ログから分析。ReAct エージェントに既に存在した動画生成ワークフローを、フロントの独立サーフェスとして開放した話。
#個人開発#UX#クリエイティブAI
HiDream-O1-Image を 3〜8 倍速く使う: steps / CFG / 解像度の実測ベンチ
HiDream-O1-Image Full の steps / CFG / 解像度を同一 prompt / seed で振り、生成速度と品質の落とし所を実測した記録。
#hidream#diffusion#imagegeneration
言語学習ショート動画を Claude Code で再現してみた — Gemini を sub-agent 化したマルチモーダル拡張
Pingo 風言語学習ショート動画コメディを Claude Code 開発環境でローカル GPU + Gemini 3.1 Pro Preview のハイブリッド構成で再現した話。サブエージェント化でメイン agent の context を膨らませず editorial signal だけフロンティアに委ねる。
#claudecode#gemini#ai