RTX PRO 6000 Blackwell Max-Q 入手了。96GB VRAM、Blackwell 世代、面向专业工作站的 GPU。对于个人来说,这显然是一笔巨大的开销。
这既不是 GPU 的开箱记录,也不是基准测试文章。而是关于我如何花了五年时间才走到这一步,以及买下它之后发生了什么变化的故事。
关于“96GB 能设计出什么”的技术实测,我另写了一篇文章,基于服务栈进行了测量。这篇,则是那之前漫长时光的故事。
用3万日元的Chromebook学习
我学习编程时用的机器,是一台3万日元的Chromebook。
对当时的我来说,那是唯一能买得起的现实机器。但对于想做 AI 的人来说,3万日元的 Chromebook 实在太弱了。
别说本地 LLM,就连稍微重一点的开发环境都吃力。我一边想着“总有一天,想要一台像样的 GPU”,一边度过了相当长的时间。
在Colab上凑合的日子
我也用过 Google Colab。用免费额度或便宜的 GPU,勉强尝试了一些像样的东西。
选择能跑的模型,写能跑的代码,做能跑的实验。
但那始终是一种“凑合”的感觉。真正想碰的东西跑不动,稍微贪心一点就崩溃,会话会断开,每次都要花时间搭建环境。
借来的 GPU、借来的时间、借来的实验场所。感觉就像把自己的梦想寄托在别人的便利上。
这期间 AI 飞速发展。GPT 出现了,LLM 爆发式普及,开源模型也越来越强。时间线上,总有人用强大的机器尝试开源模型并分享见解。
我也想去那边。
进了AI创业公司,但……
我好不容易进了一家 AI 创业公司。但公司的氛围相当糟糕,不是能继续待下去的环境。
即使技术有趣,如果环境崩坏,人也会崩坏。明明终于接近了 AI,却在那里被一点点消耗。
不过,对 AI 本身的兴趣并没有消失。反而“想在自己的环境里做”的念头更强烈了。
成为自由职业者后,终于能考虑投资了
之后我成了自由职业者,大约半年后,终于开始考虑“为自己做一次大投资”。
那时,我脑海中第一个浮现的就是 GPU。
按理说,有无数更稳妥的花钱方式:存款、税金、生活应急资金、工作用电脑的升级。但多年来一直因为“机器太弱”而放弃的事情,如果在这里又说“总有一天会买”,那个“总有一天”又会变得遥遥无期。
不过,在这个时间点决定买 GPU,背后还有更复杂的原因。
买之前的我,相当低谷
把时间往回拨一点。
买这台机器前不久,我的主力产品还是高质量头像对话,使用的 GPU 是 RTX 4000 Blackwell,VRAM 24GB。当时支持的 TTS 引擎比现在多,为了塞进去,我拼命量化、尝试用 TensorRT 编译。即便如此还是不够,不得不忍痛隐藏了多语言性能出色的 Qwen3-TTS。一直是在和 VRAM 战斗。
好不容易发布了。但 PV 几乎为零。用户也是零。
与此同时,我也尝试了副线计划:面向小型餐饮店和诊所的语音预约自动化销售。但结果惨不忍睹。现在想想也是理所当然——去向“自动化会让电话接线员失业的人”推销这个产品,本身就是矛盾的销售。连和经营者好好说话都做不到,成果为零。只有精神被消耗殆尽。
很不甘心。我对语音部分的 UX 很有信心。因为有 ReAct 代理的基础,不仅能处理简单预约,还能应对复杂任务。即使以某语音 Lab 提供的 API 十分之一的价格提供,利润率也超过 90%。从技术上看,我看不到自己会输的理由。——正因为近乎执念地投入,不被认可的不甘才格外强烈。
(那段时间的副产品,比如自动拨号系统,留在了手边。现在想来,那些辛苦并没有完全白费。)
连演示都没人听
在那期间,我决定在所属的工程师朋友群里做一次演示。打算提议请他们帮忙吸引关注。
但结果——似乎没人感兴趣。甚至表现出“连演示都不想听”的态度。
说实话,很受打击。竟然到了这种地步?我的人望就这么差吗?真是跌到了谷底。
“红海没有胜算”“设计太简陋”——各种所谓的反馈都有。
但是,我想。连演示都不听,这种肤浅的声音,还不足以让我的产品动摇。
那天,我退出了那个群。差不多算是闹翻了。然后我决定更专注于这个产品。下定决心买下170万日元的 GPU,也是在那天。
颤抖着手指下单
按下购买按钮时,手在发抖。“真的要买吗?”“这正常吗?”“失败了怎么办?”
转账时,银行怀疑我,交易被冻结了。也难怪,突然要买这么贵的 GPU。但对我来说,这是在赌上人生的某些东西,所以被阻止的那一刻相当焦虑。
折腾了一番,最终还是买到了。到手的那一刻,我觉得这不仅是 GPU,更是我没有放弃的时间的结晶。
意外的惊喜
如果故事到这里就结束,那只是一个孤独决别的故事。
但,有个意外。
退出群之后,他们中的一个人联系了我。听了我的决心后,他说:
“既然这家伙要赌上人生去挑战,那我也只能帮忙了。”
然后,他就直接跳进了项目。新成员加入了。
就像《火焰之纹章》里,之前还是敌人的背叛剑士,在某一章突然加入我方时的那种——久违的兴奋感。
一个人没有放弃的结果,就是这块 GPU。而因为决定不放弃继续前进,回来的,是这个伙伴。
即便如此,我不想只把它当成一个煽情的故事
我不想以“买了真好”就结束。所以,我认真用数字验证了这 96GB 在个人开发中能实现什么。
只写一个对我而言具有象征意义的瞬间。
运行语音角色扮演和从分镜自动生成视频的管道。一个请求,就能让本地 LLM、图像生成、TTS、唇形同步、视频生成在时间轴上依次触发。如果 reviewer 说“这个场景重来”,就全部重新调用。能否在不每次重新加载模型的情况下运行这个反馈循环,是 24GB 时代无论如何也跨不过去的墙。
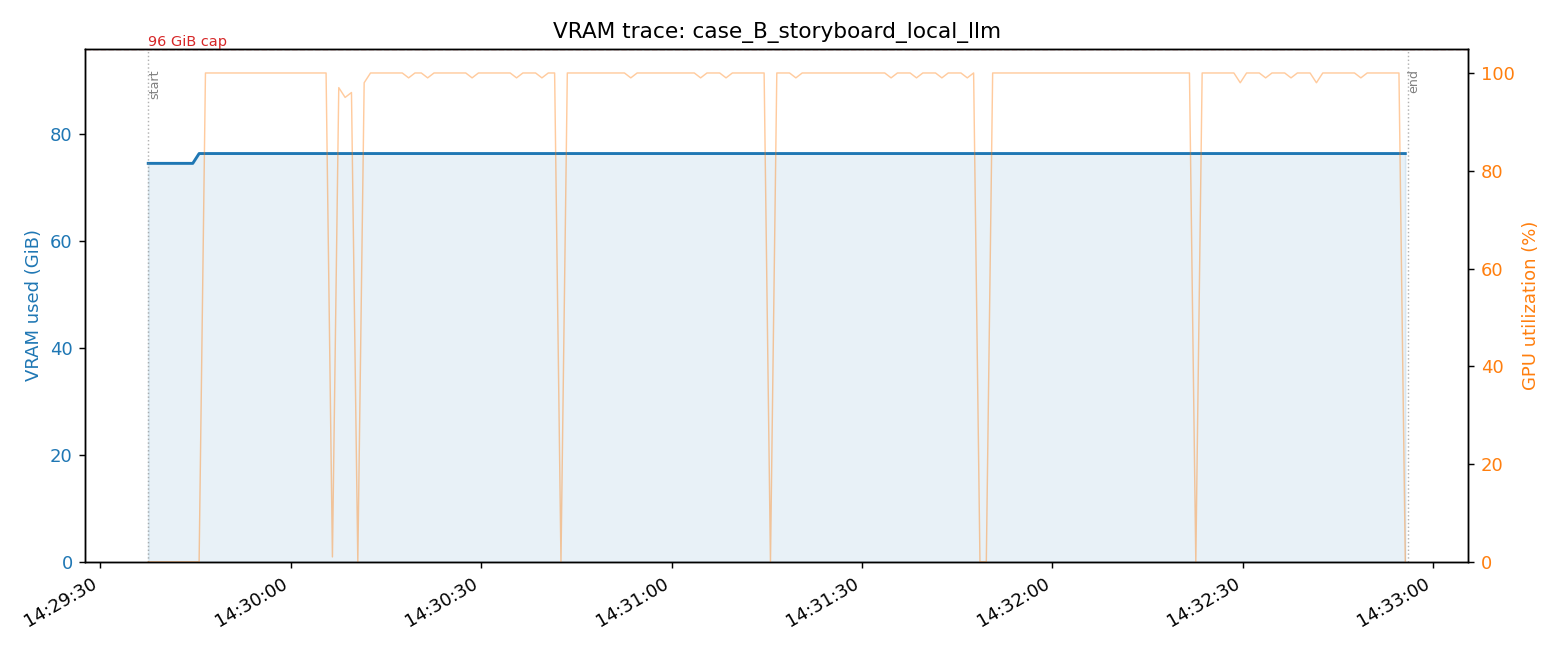
换到 96GB 后,让所有模型常驻,运行分镜生成时,VRAM 几乎没动。+1.9 GiB。所有模型保持 warm,只有计算在跑。那一刻,我意识到“买的不是容量,是常驻”。
这些实测数据(idle 基线、生成一段视频时的 VRAM 峰值、与本地 LLM 共存、以及 96GB 也无法跨越的边界线)都写在技术篇里,附有追踪图像。
→ 五年后,我拿到了96GB VRAM —— 代理循环能跑起来的 GPU 的故事(技术篇)
能做什么了
买下后的几周内,已经跑起来的东西。
- Kotonia(语音角色扮演) — VAD + STT + LLM + 多语言 TTS + Ditto 唇形同步的实时对话。主业产品。
- 分镜 → 视频自动生成管道 — 从一个想法到 5 beat 结构的短视频,几分钟内完成。
- HiDream Studio(免费公开中) — OpenWeight 最高水平的图像生成,在 96GB GPU 上常驻运行。
- Codex CLI + 本地 Gemma 4 — 将兼容 OpenAI 的本地 LLM 作为子代理,API 零费用运行 CLI agent。
这些,在借来的 GPU 上都是“总有一天”的事。
总结
大约五年里,我一直说“机器太弱,做不到”。现在,这句话正在一点点成为过去。
GPU,只是计算资源。但对我来说,它也是没有放弃的时间的具象化。接下来,是用它来做什么。