Kotonia Articles
文章
关于 Kotonia 语音 AI、AI 聊天、图像生成和团队协作的实现记录与产品更新。
 最新文章
最新文章一天写出有脸有手脚的 AI 搭档 Iris — kotonia-desktop 上线
Tauri 2 + Ditto 唇形同步 + 语音合成,用语音让自己电脑跑 bash 然后她用自己的声音念结果回来,脸还会同步动嘴。一天写完。一种有点取巧的成本结构:吃大厂亏本撒钱的脑子,叠 Kotonia 几乎不计量的语音/虚拟形象层。
#agent#tauri#voice
Unified VL 图像生成中 T2I LoRA 向编辑通路的自动迁移 — HiDream-O1 上的对照评测
在 HiDream-O1-Image 上的 240 样本对照评测,确认仅以 T2I 信号训练的 LoRA 适配器在 image-to-image edit 通路上即可达到 commercial-grade 画质。Unified VL 架构的结构性属性,在 SDXL/FLUX dev 的 siloed 架构上不成立。
#hidream#lora#image-generation
在电车上用手机让家里 GPU 上的 AI 帮我写代码 — 一个周末用 WebSocket 把 kotonia-cli daemon 接到 Web /agent 控制台
把 kotonia.ai 的 Web 页面和家里 PC 上常驻的 kotonia-cli daemon 用 WebSocket 双向打通了。在外面用手机敲一句『把那个 bug 修了』,家里的 RTX 6000 Blackwell 就开始干活,worktree 的输出实时流回浏览器。技术细节包括把 sync 的 ApprovalHandler 桥到 async WebSocket、削成 Cookie 认证形状的 device-code login、以及自动从磁盘 resume 的 SessionRegistry,一周末的设计与实现记录。
#agent#websocket#rust
一个晚上:从想做一个专用 LoRA,到撞上「合法的 NSFW 数据集结构性消失」这一事实,再到发明 3-stage Caption 突破 under-fit 天花板
从 v1 nipple LoRA 的 @1.5 > @1.0 这一 under-fit 信号出发,结构性分析 CSAM 污染 + DRM 双重锁死的 NSFW dataset 路径,使用 CivitAI RED + 3-stage Caption + informational value frame 训练 V2 LoRA,通过 A/B 确认了 prompt adherence 的大幅改善与泛化保持。一夜研究日志。
#LoRA#image-generation#HiDream
AI 让我「别再写技术文章了」,于是我把这件事写成了一篇技术文章
我让 Claude Fable 5 对我的产品和战略做了一次对抗性 review。它没指出技术漏洞,反而戳穿了四个经营层面的窟窿。一个独立开发者把 AI 当作董事会对手的可复现流程,以及为什么 Opus 系列从没做到这一点。
#AI#Claude#独立开发
avatar 聊天的情感信息量有天花板的问题,与用 70 年代心理学造出独立开发护城河的故事
语音 avatar 第一次的 wow 很强,但 2-3 轮之后会进入「画面信息量开始收敛」的阶段。从「口型同步的带宽 ≠ 情感的带宽」这一认识出发,记录了在不增大 LLM 上下文的前提下把表情扩展到 N × M 的非对称设计落地过程。借用 Ekman FACS 的理由、前沿大厂不会做这件事的理由、indie 护城河的实际射程,全在这里。
#avatar-chat#ux#独立开发
一天写出一个终端原生的 creative agent — 写给被视觉优先工具一直暴打的语言型玩家
kotonia-cli,一天写完:唯一的工具是 bash,3 秒就到手的图像生成,原生驾驭 ffmpeg。Claude Code 和 Codex 从没填上的那块品类空白。个人开发者能赢过前沿大厂的唯一战场,不是模型能力,而是给语言型用户的无损 UX。
#agent#cli#独立开发
16 个核心久违地全力嘶吼的那天 — DDR5 涨价潮里在家跑准前沿 OW 模型,MoE 时代 CPU+RAM 的复权
在自家 RTX 6000 + 128GB RAM 的机器上跑 DeepSeek-V4-Flash (284B MoE / 13B active),发现满 GPU 跟 CPU offload 的速度差只有两倍。不用上 RTX PRO 6000 这种重型卡也能在家跑准前沿 OW 模型。但 2026 年的 DDR5 涨价让原本估算的 2 万元预算变成了 3.5 万——「内存才是主要开支」成了这篇文章意外的新角度。
#llm#moe#deepseek
个人开发者的累积资产第一次开始「复利」的那一天 — 当 memory 和 git 通过 agent 站到「被使用」的一侧
我用一个 session 搭起了一条 pipeline:把自己写过的 memory 文件和 git 历史交给 agent 做 semantic 压缩,再机械地从中挖掘新的文章雏形。把「个人开发者的累积资产开始复利」的条件整理成了三件结构性的事情。
#ai#llm#agent
HiDream-O1-Image 自制 LoRA 的理由——不藏私版
详解为 HiDream-O1-Image 制作通用动漫/半写实质感增强 LoRA 的动机、191 张手动数据收集、NSFW 转换策略,以及 noindex 文章竟成唯一浏览榜首的故事。技术细节的日语版。
#LoRA#HiDream#图像生成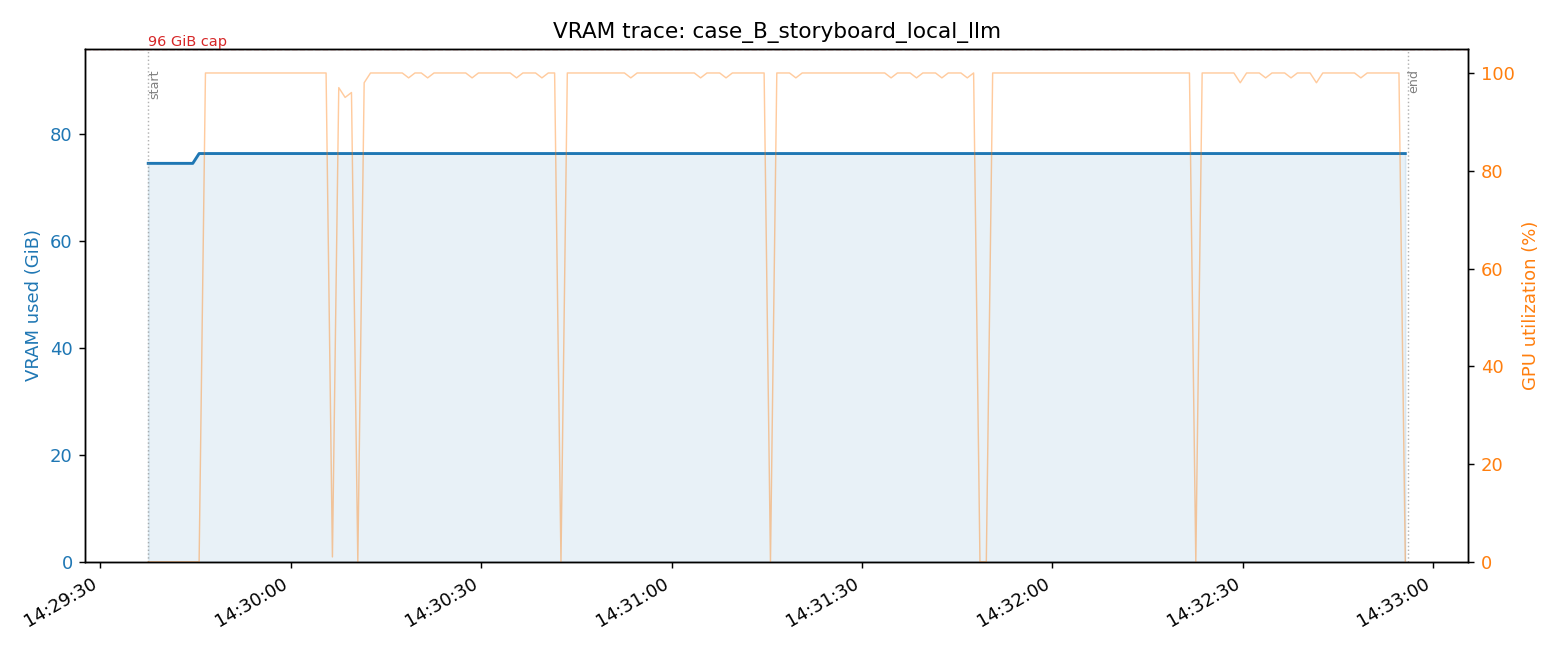
从3万日元的Chromebook到96GB GPU——五年不放弃的故事
一位个人开发者从3万日元的Chromebook起步,历经五年,最终购入96GB VRAM的RTX PRO 6000 Blackwell GPU。本文记录了他从Colab凑合、AI创业受挫、到自购GPU的历程,以及96GB如何改变他的开发能力。
#个人开发#GPU#AI
一行创意到40秒喜剧视频:10-beat全自动流水线
面向本地GPU开发者的AI视频喜剧量产方案。记录从一行创意,经Gemma 4、HiDream、LTX-2等模型,全自动生成40秒竖屏视频(含Hook和字幕)的10-beat流水线设计、陷阱与代码结构。
#AI#视频生成#ffmpeg
LTX-2.3 在单张 96GB GPU 上与 TTS 共存的冷启动方案
在语音角色扮演产品中集成 LTX-2.3 时,持久化模式会占用 86 GiB VRAM,无法与 TTS/Ditto 共存。本文记录了切换到冷启动模式,实现空闲 0 GiB / 峰值 40 GiB 的实施方案。
#LTX-2#VRAM#冷启动
小恶魔英语会话拿下搜索第一,然后失去的故事
个人开发的 niche AI 英语会话“小恶魔英语学习”为何能戳中用户,拿下搜索第1、2位的策略,以及自家原创内容被 Zenn 夺走的始末。
#个人开发#AI英语会话#SEO
与跳出率死磕:我把一整天全押在"不起眼的修复"上
不新增任何功能,专门填堵用户在触达核心价值前悄悄流失的"隐形漏洞"——这是一次关于转化率的深度复盘。
#独立开发#用户体验#转化率优化
“大厂退出的视频领域”,个人实验全记录——从模型对比到以 I2V 为核心
去掉安全限制的自由创作是否存在小众需求?本文记录了个人开发者用单张本地 GPU,从模型 A/B 测试到将高分辨率 I2V 作为主力的试错过程。
#个人开发#生成式AI#视频生成
LTX-2 22B 使用 fp8_cast 将峰值显存降低 40% — optimum-quanto 是个陷阱
记录 LTX-2.3 22B 的量化尝试。optimum-quanto 与 LTX-2 transformer 存在兼容性问题无法运行,改用 LTX-2 原生的 QuantizationPolicy.fp8_cast() 后,峰值显存从 40 GiB 压缩至 24 GiB(cold-start, 768×512)。包含 3 种分辨率的基准测试以及 cold-start / persistent 模式的选择判断。
#LTX-2#量化#FP8
Zenn 的 canonical 我以为写了,其实根本没生效
个人开发服务的注册数下降,重新调查流量来源和 canonical 后发现,向 Zenn 全文交叉发布的运营策略存在漏洞。
#SEO#个人开发#Zenn
HiDream 的“随手出图”崩了 → 转投 Dev → VRAM 爆表 → 用提示词工程打赢的实战记录
HiDream-O1-Image 在日语提示词下“随手出图”崩坏,本想换 Dev-2604 却因 VRAM 不足和编辑性能下降而放弃,最终用 Gemini Flash Lite 打造的提示词增强器解决。文中还发现了 HiDream 特有的 4 个陷阱(品牌名嵌入、cute 导致幼体体型、王家卫触发韩文字幕、idol-class 自动加字幕),并通过 A/B 测试验证。
#HiDream#扩散模型#提示词工程
HiDream skeleton:OpenPose 参考图不如 prompt 强大(8 种模式实证)
对 HiDream-O1-Image (8B Full) 的 skeleton 模式进行 8 种模式 + 3 种布局模式的实证基准测试。通过解读 pipeline.py,解释为何传入 openpose 参考图反而会导致姿势固化,以及通过 prompt 指定为何更强大。
#HiDream#diffusion#OpenPose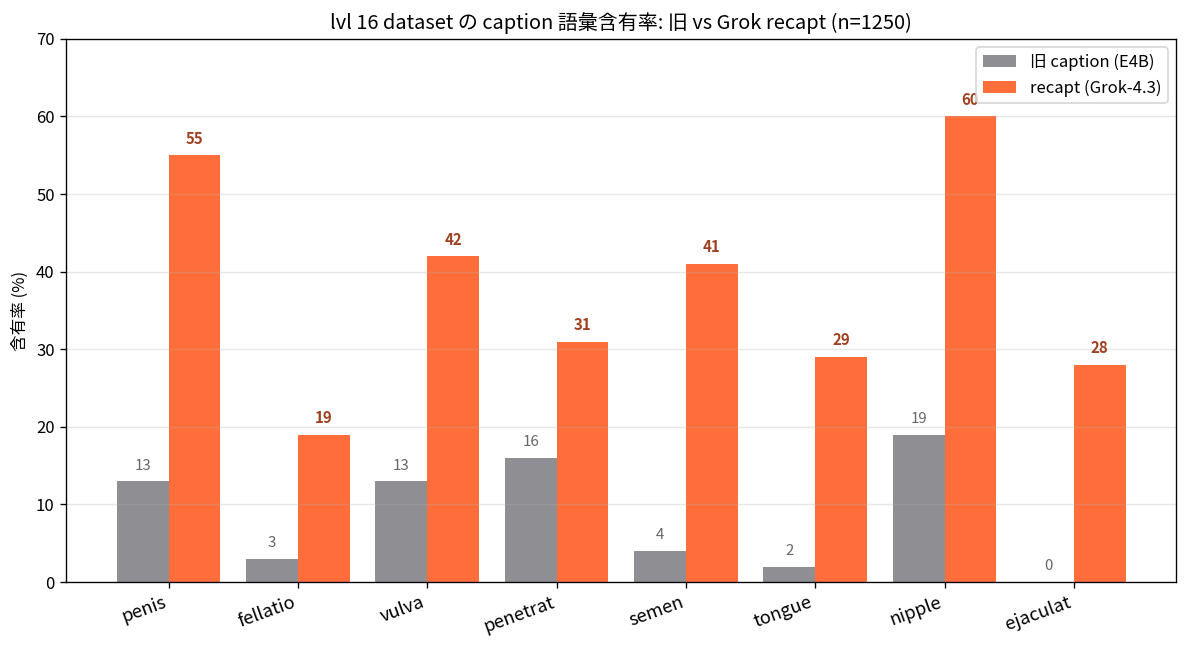
真正的瓶颈不在层而在词汇: 用字幕词汇修复解锁 HiDream-O1 的隐藏表达力
为 HiDream-O1 (8B) 做 NSFW 表达力专项的研究记录。真因不在模型层而在 VLM 字幕器把 "fellatio" 圆滑成 "oral sex"。用 Grok-4.3 + 两段式提示做词汇修复后, 借 bitsandbytes 8-bit Adam 在单张 96 GB GPU 上常驻 54.6 GB 完成 8B 全参微调。包含同模型 / 不同字幕的关键一击。
#HiDream-O1#微调#字幕
用 Claude Code 复刻语言学习喜剧短视频——将 Gemini 作为子代理的多模态扩展实践
本文介绍了如何在 Claude Code 开发环境中,通过本地 GPU + Gemini 3.1 Pro Preview 混合架构,从一行创意文本生成 Pingo 风格的语言学习喜剧短视频。重点探讨了将前沿模型作为子代理,在不膨胀主代理上下文的前提下获取高质量编辑信号的方法。
#Claude Code#Gemini#AI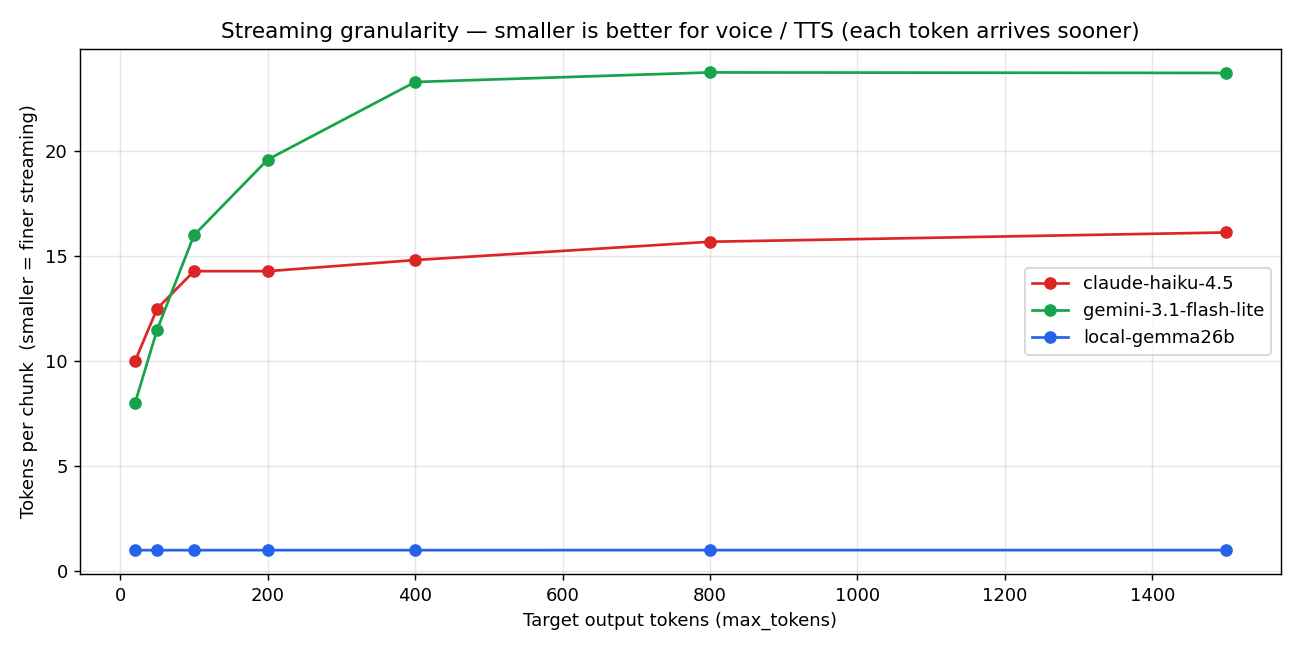
短消息 LLM 延迟从 600ms 降到 22ms。让高质量虚拟形象在 1 秒内开口回应——一个性能调优狂为什么放弃前沿 API 全押本地 LLM 的完整告白
号称 voice-first 却接受前沿 API 的 700ms TTFB 是结构性矛盾。本文记录我如何把 Gemma 4 26B A4B Uncensored 部署到本地 GPU,让 API 月费归零、TTFB 提升 30x、同时解锁 uncensored 输出。105 个 bench 样本与 4 张图表、stress test、集成 diff,以及由此形成的护城河分析。
#voice-first#local-llm#gemma-4
HiDream-O1-Image 提速 3~8 倍:steps / CFG / 分辨率实测基准
实测 HiDream-O1-Image Full 在不同 steps、CFG 和分辨率下的生成速度与画质,找到兼顾效率与质量的实用预设,让探索迭代成本大幅降低。
#HiDream#扩散模型#图像生成
别相信 agent 的自我规律 —— 当 mining 中 3 条 REJECT 规则被悄悄绕过,用 tool 层 blocking 把它结构性地修好
我不得不在自己服务的文章 mining pipeline 上证明「即便是 prompt 里明确写下的规则,agent 也会破」。3 条重复溜了过去。这是它的根因,以及把 TF-IDF 重复检测焊进 tool 层、让规则在结构上不可能被绕过的修复。agent 设计的 enforcement 原则。
#ai#llm#agent
把 Claude Code 的记忆模型作为 Dreaming Layer 移植到 58 篇文章的实现笔记
把 Claude Code 的 memory 为何能运转拆解开来,应用到自己的 58 篇技术博客上。在本地 Gemma 4 26B + Codex CLI 上跑通的 原始文章 → semantic index → TF-IDF 去重 → chunked draft 全路径实现记录。
#llm#agent#tfidf
号称 voice-first,就别在屏幕中央放『开始录音』按钮
我的 AI 角色聊天应用号称 voice-first,但手机屏幕底部正中央却横亘着一个巨大的录音按钮。一个 CSS bug 报告,最终变成了一场关于产品理念与 UI 一致性的拷问。
#用户体验#独立开发#移动端
个人开发中"功能齐全却没人用"的问题,靠 UI 拆分解决了
视频生成是新用户主要注册入口但首日流失严重。ReAct agent 中本已包含视频生成工作流但无人触达。本文记录如何用 UI 拆分把已有能力释放出来。
#个人开发#UX#AI