
打开系统监视器,发现 16 个 CPU 核心几乎全部贴到 100%。这种景象好久没看到了。
平时这台工作机 (RTX PRO 6000 Blackwell Max-Q + RTX PRO 4000 BW + 16 核 / 128GB RAM),CPU 是不会这样嘶吼的。出图、出视频、出声音,全都甩给 GPU,CPU 只负责 I/O 协调和预处理。
然后我点了一下 DeepSeek-V4-Flash 的启动,全部核心瞬间满载。「在以 GPU 为中心的世界里,CPU 又重新登场了」——这种小小的违和感,是这篇文章的起点。
1. 我到底在做什么
今早把内存升到 128GB,重启了机器。「128GB 的话,应该能把 DeepSeek-V4-Flash 的大部分专家用 CPU offload 跑起来」——抱着这个念头随手试一下。
DeepSeek-V4-Flash 是 2026 年 4 月发布的 OW Mixture-of-Experts 模型,284B total / 13B active,1M context,MIT 协议。和同时期的 GLM-5.2 (~750B/40B active)、Kimi K2.6 (1T/32B active) 一起,是目前 OW 最强一档的代表。
云 API 价格是 $0.14/M input,做成商业产品的部分早就标准化了。但要把这一级别的模型 跑在家里,就是另一回事。
| 模型 | total / active | IQ2_XXS GGUF | 在家能跑吗 |
|---|---|---|---|
| DeepSeek-V4-Flash | 284B / 13B | ~73 GiB | 能跑 ← 这次 |
| GLM-5.2 | ~750B / 40B | ~239 GiB | 没 256GB RAM 不行 |
| Kimi K2.6 (INT4 native) | 1T / 32B | ~250 GiB | 同上 |
| Qwen3-235B-A22B | 235B / 22B | ~70 GiB | 能跑,但智能比 V4-Flash 差 |
也就是说,284B / 13B active 这个量级,差不多就是「个人机器能装下的 OW 智能上限」。再大的就得砸 256GB RAM 的投资。
2. 把 OW 用 Agentic Index 摆一遍,V4-Flash 的独特位置就显出来了
下面是 Artificial Analysis 最新的 Agentic Index (GDPval-AA v2 + τ³-Banking 的平均),OW 排名长这样:
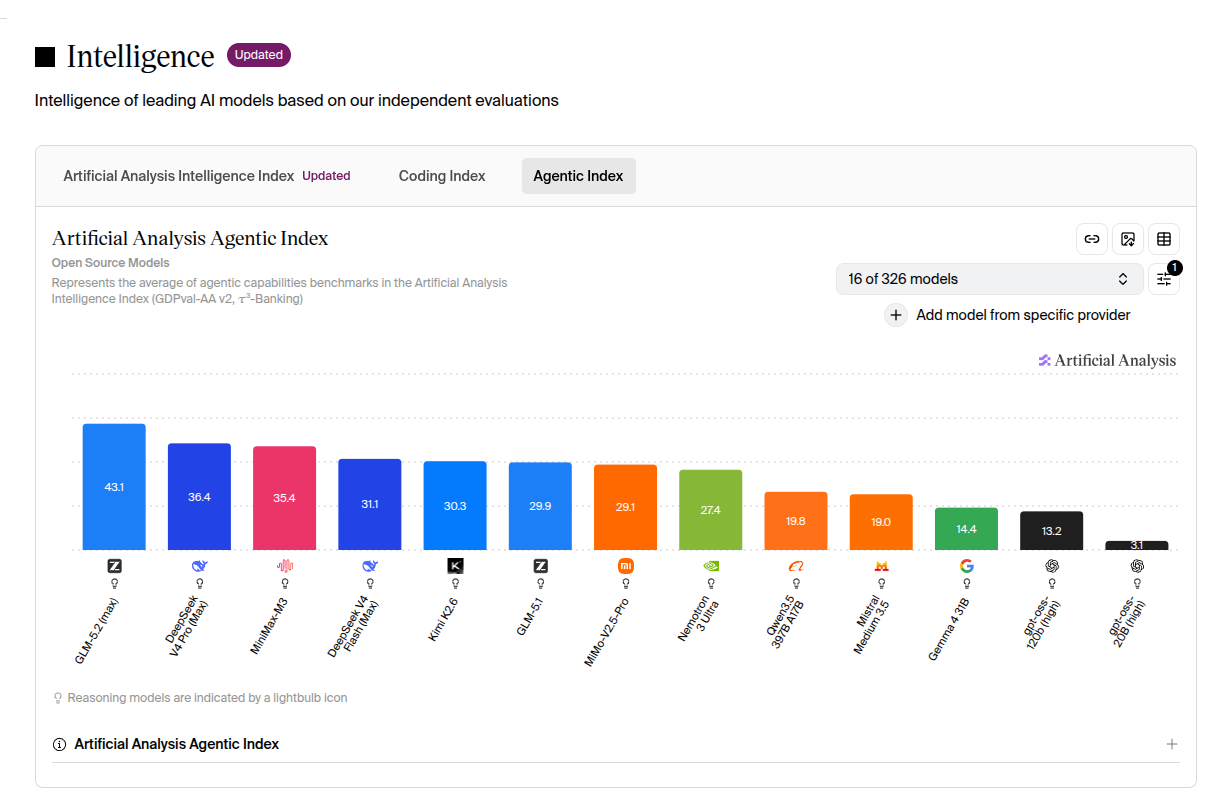
光看数字:
| 排名 | 模型 | Agentic Index | total / active | IQ2 GGUF |
|---|---|---|---|---|
| 1 | GLM-5.2 (max) | 43.1 | ~750B / 40B | ~239 GiB |
| 2 | DeepSeek V4-Pro (Max) | 36.4 | 1.6T / 49B | ~430 GiB |
| 3 | MiniMax-M3 | 35.4 | 428B / 23B | ~110 GiB |
| 4 | DeepSeek V4-Flash (Max) | 31.1 | 284B / 13B | ~74 GiB ★ |
| 5 | Kimi K2.6 | 30.3 | 1T / 32B native INT4 | ~250 GiB |
| 6 | GLM-5.1 | 29.9 | (上一代) | — |
| 7 | MiMo-V2.5-Pro | 29.1 | — | — |
| 8 | Nemotron 3 Ultra | 27.4 | — | — |
| 9 | Qwen3.5 397B A17B | 19.8 | 397B / 17B | ~100 GiB |
| 10 | Mistral Medium 3.5 | 19.0 | — | — |
| 11 | Gemma 4 31B | 14.4 | 31B dense | ~20 GiB |
| 12 | gpt-oss 120b (high) | 13.2 | 120B / 5.1B | ~30 GiB |
但只要加一层约束 ——「家用 128GB RAM 配置 (2026-06 当下因 DDR5 涨价基本上要 3.5 万元档),能不能用得动 (10 tok/s 以上)」——图就完全变了:
| 模型 | 在家 128GB RAM 上能跑吗 | Agentic Index |
|---|---|---|
| GLM-5.2 (43.1) | ❌ swap 抖动,1-3 tok/s | 43.1 |
| V4-Pro (36.4) | ❌ 内存根本不够 | 36.4 |
| MiniMax-M3 (35.4) | △ 卡边缘,KV + working buffer 一上就 OOM | 35.4 |
| V4-Flash (31.1) | ✅ 128GB 还能剩 50GB,实测 11.8 tok/s | 31.1 |
| Kimi K2.6 (30.3) | ❌ 至少要 256GB+ | 30.3 |
| Gemma 4 31B (14.4) | ✅ 能跑,但智能差太多 | 14.4 |
也就是说 「在家 3-4 万元档能实际跑动的 OW 里,Agentic Index 最高的就是 V4-Flash」。光看 31.1 是第 4 名,但只要加上「上面 3 个家里跑不动」这个条件,V4-Flash 就 实质性地升到第一。
这是个人开发者现在面对的真实选择,性价比的最佳点就压在 V4-Flash 身上。
3. MiniMax-M3 跟 V4-Flash,分水岭在哪
顺便看一下 第 3 名的 MiniMax-M3 (428B / 23B active,2026 年 6 月发布)。它的 Agentic Index 比 V4-Flash 高 4.3 分,编程基准 (SWE-Bench Pro 59.0%) 上甚至超过了 GPT-5.5 / Gemini 3.1 Pro。作为单纯的模型评估,M3 明显更强。
但只要进了家用机的话题,分水岭就一目了然:
- 总参数 428B vs 284B → IQ2 下 110 GiB vs 74 GiB
- active 23B vs 13B → 每个 token 在 CPU 上要算的量 多 1.8 倍
- 128GB RAM 的情况下:M3 加上 KV cache + working buffer 就 OOM 边缘出局,V4-Flash 还能留 50GB 余量
要在家舒服地跑 M3,得把 RAM 升到 192GB 或 256GB。一年前这块投入还是 5000-7000 元的事,2026 年 6 月已经变成 再加 10000-15000 元。墙变得比从前更高了。
也就是 「在 128GB RAM 这条线上,刚好能踩进去的 OW 是 V4-Flash」。M3 已经掉到线的那一头去了,而且 DDR5 涨价让这个差距变得更扎心。
这是「性价比最强」这个词难得能成立的一种场景——上面的智能分数都在收敛,只有 内存占用这一项还保持着尖锐的差异。
4. 「16 个核心嘶吼」到底是怎么回事
MoE 模型的推理跟传统 dense 模型本质不同。
DeepSeek-V4-Flash 有 284B 参数,但 生成一个 token 实际只用 13B 的权重。256 个 expert 里,每次只选 6 个去算;剩下的 250 个跟当前 token 无关,留在内存里待命就行。
这里就出现了一个战略分叉:「权重放 GPU,还是放 CPU 这边的 RAM」。
- 全放 GPU:VRAM 需要 74 GiB。RTX PRO 6000 (96GB) 够。普通的 RTX 5090 (32GB) 完全不行。
- 只把 expert 放 CPU RAM (
-cmoe路线):VRAM 只需要 7 GiB。普通的 RTX 5070 级 (16GB) 也能装下 attention 部分。代价是要 128GB RAM,且 每一个 token 都要在 CPU 上算 13B 的 expert weight。
选第二种配置,CPU 的所有核心就要真刀真枪干起来。llama-server 的 -t 16 把 16 个线程全压到 expert 计算上。这就是我今早看到的「16 个核心 100% 贴满」的真相。
「CPU 又重新成主角了」是当下的第一反应,但更冷静的说法是:GPU 和 CPU 进入了分工时代。
5. 硬件配置与复现成本
把我这台机器的实际配置,跟「最小可复现的准前沿 LLM 盒子」并排放一下:
| 部件 | 我的配置 | 最小复现配置 | 2026-06 估价 |
|---|---|---|---|
| GPU | RTX PRO 6000 BW Max-Q (96GB) | RTX 5070 (16GB) 就够 | 约 6500 元 |
| 内存 | 32GB × 4 = 128 GB | 32GB × 4 = 128 GB | 约 15,000-22,000 元 ← 涨疯了 |
| CPU | Ryzen 9 (16 核) | Ryzen 9 7900X (12 核) 即可 | 约 4000 元 |
| 主板 + 电源 + SSD + 机箱 | (略) | 一整套 | 约 3500 元 |
| 合计 | 约 3.0-3.6 万元 |
说实话,最初动笔写这篇文章时,我预算的是 2 万元能搞定。但 2026 年开始的 DDR5 涨价潮 把这个估算冲烂了。详情下一章细说,32GB DDR5 单条 $375 (约 2700 元),比一年前的 $80-120 涨了 400% (Tom's Hardware, 2026-06)。
不过结构性的结论依然成立:「不用买 RTX PRO 6000 这种 100 万元级重型卡,总预算 3 万多元就能在家跑准前沿 OW」。变化是 主要开支从 GPU 转移到了 RAM,这本身就成了 MoE 时代的一个独立故事。
下面有一个值得强调的发现。
6. 满 GPU 跟 CPU offload 的速度差 比想象的小
今天测的数据,相同的 DeepSeek-V4-Flash IQ2_XXS-XL GGUF,相同的 prompt (Fibonacci 任务,~800 token 生成),只改拓扑:
| 拓扑 | VRAM | RAM 占用 | gen tok/s |
|---|---|---|---|
| 满 GPU (GPU0 单卡, KV fp16) | 76 GiB | 16 GiB | 20.0 ← 最快 |
| 满 GPU (multi-GPU split) | 76 + 11 GiB | 16 GiB | 13.6 (PCIe split overhead) |
| 满 GPU (KV q8_0) | 76 GiB | 16 GiB | 16.3 (反而变慢) |
CPU MoE (-cmoe) | 7 GiB | 76 GiB | 11.8 ← 普及档目标 |
这里最值得强调的是 「20 tok/s vs 12 tok/s」这个差距,比直觉小得多。
V4-Flash IQ2 量化是 74 GiB。RTX PRO 6000 (96 GB VRAM) 装得下整个,所以可以吃满 VRAM 带宽 1700 GB/s。理论上限约 430 tok/s。
但实测只有 20 tok/s = 理论的 5%。为什么?
答案是 「llama.cpp 的 cchuter fork 还是 WIP」。DeepSeek-V4 引入了 MLA / CSA / HCA / Lightning Indexer / Hyper-connection / Gated Delta Net 等大量自研 op,对应的 CUDA kernel 都还没调好。DeepSeek 自家的 inference 栈 (FlashMLA + DeepEP + DeepGEMM) 能跑出量级以上的差距,但第三方 llama.cpp 还停在「让它跑」的阶段,没走到「让它快」的阶段。
也就是说,GPU 的真实能力没被榨出来,所以跟 CPU offload 的差距才被压小了。
这是一个 「时间会解决」 的问题。
等 cchuter fork 合入 upstream 主线,CUDA kernel 调好之后,满 GPU 大概率能上 50-100 tok/s 档。但 CPU offload 这边,IQ2 dequant kernel 和缓存局部性这块还能再榨 +50% 出来,最终的比例其实说不准。
但 「现在的对决是 20 tok/s vs 12 tok/s,所以买重型 GPU 的差异化理由很薄」——这是当下个人开发者要面对的现实。
7. 为什么 MoE 时代 CPU+RAM 会「复权」
dense 模型 (Llama 3 70B 等) 时代,每一步推理都要读取全部 70B 权重。带宽是真正的瓶颈,必须是 GPU 的 HBM3e (3-5 TB/s) 才有资格上桌。CPU 的 DDR5 带宽 ~100 GB/s,慢了 30-50 倍。
MoE 时代规则换了。
- V4-Flash 是 284B total,但 active 只有 13B
- 1 token = 13B 量级的内存访问
- CPU DDR5 上,13B × 2 bpw (IQ2) = ~3 GB/token
理论上 100 GB/s ÷ 3 GB = 33 tok/s 应该能跑得到。实测 11.8 tok/s,因为还要加上 CPU 的实际计算量 (dequant + matmul),但量级是对得上的。
也就是说,MoE 其实是 「把带宽需求砍到原来 1/20」 的一项发明。这把 CPU 和 GPU 的差距从「数量级」拉回到 「2-3 倍」。
但这里有个讽刺的现实。
128GB RAM 现在已经不是「3000 元就能买到」了。
32GB DDR5-5600 × 4 ≈ 1.5-2.2 万元 (2026-06)
一年前 32GB 一条 $80-120 (~600-900 元),128GB 凑齐大概 3500-5000 元能搞定。然后 2026 年的 AI / 服务器需求把 DDR5 价格直接拉高 400%,现在 32GB 单条 $375 (约 2700 元),128GB 要 1.5-2.2 万元。业界共识:缓解要等到 2027-2028 年才有望 (Tom's Hardware、TechTimes)。
也就是说:「MoE 让 CPU+RAM 终于能跟 GPU 一较高下了 → 紧接着 AI 需求把 RAM 价格也拉到天上」——两头同时被挤。
不过换个角度看,这其实是市场在说 「对 MoE 推理来说,内存值得 GPU 级别的资本投入」。「两块 RTX 5070 Ti 的钱,全部花在内存上」——这种说法三年前会被嘲笑,MoE 时代的今天对个人开发者来说也变成了合理选择。
把主要开支从 GPU 移到 RAM —— 这就是 MoE 时代硬件投资新的优先级。
8. 实际能用来做什么
11.8 tok/s 配 256K context,确实慢。比 GPT-5 / Claude Opus 那种 80-150 tok/s 慢了 8 倍。实时对话肯定不行。
但只要场景挑对了,依然能落地。
「不需要超快」的场景:
- TRPG / 小说模式后端:作为推动故事进展的引擎,等思考 30-90 秒是可以接受的,甚至有「在认真想」的氛围。256K context 足以一次装下世界观、人物、历史
- ReAct 智能体:每步 100-300 token 的话 5-15 秒,工具调用循环 5 步加起来不到 1 分钟。普通 ReAct 范围内可以接受
- 长上下文摘要/分析:输入 32K 文档一次性总结,等 1 分钟换来高质量产出,划算
不适合的场景:
- 实时对话 (TTFB 5-30 秒)
- 批量代码生成 (单文件 30 分钟换 GPT-5 的 1 分钟,不划算)
- 对延迟敏感的工具 (搜索补全等)
也就是 「把 latency-tolerant 的高级推理放在自己机器上跑,API 成本为零」——这是核心价值。对有隐私要求的场景 (咨询、辅导、内部文档分析),自有推理的优势会更突出。
9. DeepSeek「把困难输出出去」的战略
顺便讲个技术层面的有趣观察。
DeepSeek 每次发布 (V2 → V3 → V3.2 → V4) 都会把新的架构 以 OW 形式公开论文和权重,但自家的 inference 始终跑在 自有优化 kernel (FlashMLA / DeepEP / DeepGEMM) 上。第三方每次追平大概要 3-6 个月。
可以这样读:这是把一种商业模式 写在架构层面上强制实现——「要吞吐量请买云 API,只要智能可以把权重抱回家」。
V4 的 Lightning Indexer / Hyper-connection / Gated Delta Net 在论文层面都很漂亮,但要写出调好的 CUDA kernel 真的费工夫。第三方刚做到「让它跑」,DeepSeek 已经把 V5 发布了。
「公开论文和权重,卖优化好的 kernel」 这种模式,跟 Anthropic / OpenAI 的路子完全不同,但同样具有持续性。作为个人开发者,这种思路里能学的东西不少。
10. 已上线:kotonia.ai 的 Code chat / Creative Studio 里 V4-Flash 作为 WIP 选项可选
最后说一下。今天的实验已经作为 WIP 选项推到 kotonia.ai 生产环境。
/chat/code (Code chat) 和 /chat/studio (Creative Studio) 的模型选择里,「DeepSeek V4 Flash (Local, $0, ~5-12 tok/s, WIP)」 已经可以选。选了之后,请求经过 Cloudflare Tunnel 打到我这台机器,16 个 CPU 核心就会真的开始嘶吼。
速度是已经认了的代价,所以现状是「即使慢也想试一下准前沿 OW」的用户的选项。等 llama.cpp 的 V4 支持合入主线、CUDA kernel 也调好之后,这个选项的速度会自然上来。
先把一个能动的版本放出去,让用户 能真的摸一下。这是个人开发者对前沿 OW 能做的现实贡献。
写在最后
「3-4 万元在家跑准前沿 OW」这个命题,三年前还是 「不可能」 的。MoE 架构的普及,加上 llama.cpp 系开源工作的推进,把它变成了现实。DDR5 涨价让原本期待的「2 万元搞定」目标没达成,是有点遗憾。但「能跑」和「跑不动」的差距,比「2 万」和「4 万」的差距大得多。
速度还不算完美,但 「能跑」和「跑不了」的差距,比「快」和「慢」的差距大得多。
更何况,看着自己 16 个核心久违地全力嘶吼,那种「投资在意想不到的方向上结了果」的心情,对个人开发者来讲是真的舒服。一台为 GPU 而买的机器,被 MoE 时代拉出舞台中央的 CPU+RAM 回报了一下。
为某个理由买的硬件,偶尔会以完全不同的形式焕发第二春。