
システムモニターを見たら、CPU 16 コアが全部 100% 近く張り付いていた。久しぶりに見た光景だった。
普段、自分の作業マシン (RTX PRO 6000 Blackwell Max-Q + RTX PRO 4000 BW + 16 core / 128GB RAM) で CPU がこんなに唸ることはない。画像生成も動画生成も音声合成も、全部 GPU に逃がしてあるから、CPU は I/O のオーケストレーションと前処理しかしていない。
それが、DeepSeek-V4-Flash を立ち上げた瞬間に全コアフル稼働になった。「GPU 中心の世界に戻ってきた CPU」という違和感が、この記事の出発点になっている。
1. 何をやっていたか
今朝、メモリを 128GB に増設したマシンを再起動した。「128GB あったら DeepSeek-V4-Flash をエキスパートの大部分を CPU オフロードで動かせるはず」と思いついて、軽い気持ちで試した。
DeepSeek-V4-Flash は 2026 年 4 月に出た OW 系の Mixture-of-Experts モデルで、284B total / 13B active、1M context、MIT ライセンス。同時期に出た GLM-5.2 (~750B/40B active) や Kimi K2.6 (1T/32B active) と並んで、現時点の OW 最強クラスの一角だ。
クラウド API で叩けば $0.14/M input、API レイヤは普通に商用化されている。だがこのクラスのモデルを 自宅で動かすとなると話は変わる。
| モデル | total / active | IQ2_XXS GGUF サイズ | 自宅で動くか |
|---|---|---|---|
| DeepSeek-V4-Flash | 284B / 13B | ~73 GiB | 動く ← 今回 |
| GLM-5.2 | ~750B / 40B | ~239 GiB | 256GB RAM ないと無理 |
| Kimi K2.6 (INT4 native) | 1T / 32B | ~250 GiB | 同上 |
| Qwen3-235B-A22B | 235B / 22B | ~70 GiB | 動くが V4-Flash の方が賢い |
要するに **284B / 13B active というサイズは「個人マシンに乗る OW 知能の天井」**に近い。これより上は RAM 256GB 級の投資が必要になる。
2. Agentic Index で OW を並べると、V4-Flash の独自ポジションが見える
Artificial Analysis の Agentic Index (GDPval-AA v2 + τ³-Banking の平均) で OW を並べた最新ランキングがこれだ。
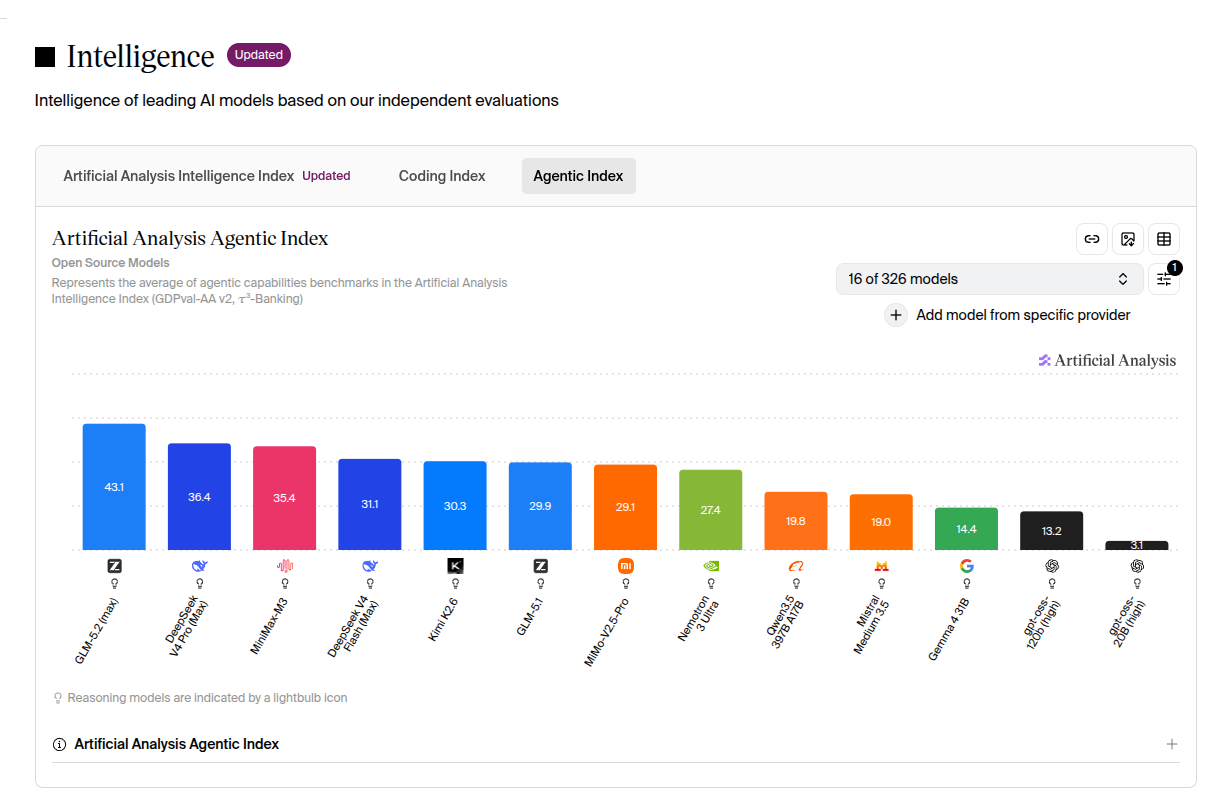
数値だけ並べると:
| 順位 | モデル | Agentic Index | total / active | IQ2 GGUF |
|---|---|---|---|---|
| 1 | GLM-5.2 (max) | 43.1 | ~750B / 40B | ~239 GiB |
| 2 | DeepSeek V4-Pro (Max) | 36.4 | 1.6T / 49B | ~430 GiB |
| 3 | MiniMax-M3 | 35.4 | 428B / 23B | ~110 GiB |
| 4 | DeepSeek V4-Flash (Max) | 31.1 | 284B / 13B | ~74 GiB ★ |
| 5 | Kimi K2.6 | 30.3 | 1T / 32B native INT4 | ~250 GiB |
| 6 | GLM-5.1 | 29.9 | (旧世代) | — |
| 7 | MiMo-V2.5-Pro | 29.1 | — | — |
| 8 | Nemotron 3 Ultra | 27.4 | — | — |
| 9 | Qwen3.5 397B A17B | 19.8 | 397B / 17B | ~100 GiB |
| 10 | Mistral Medium 3.5 | 19.0 | — | — |
| 11 | Gemma 4 31B | 14.4 | 31B dense | ~20 GiB |
| 12 | gpt-oss 120b (high) | 13.2 | 120B / 5.1B | ~30 GiB |
ここに「自宅 128GB RAM 構成 (2026-06 時点で 50 万円台、後述の DDR5 高騰込み) で実用速度 (10 tok/s 以上) が出せるか」のレイヤーを重ねると、絵がガラッと変わる。
| モデル | 自宅 128GB RAM で動くか | Agentic Index |
|---|---|---|
| GLM-5.2 (43.1) | ❌ swap thrash、1-3 tok/s | 43.1 |
| V4-Pro (36.4) | ❌ メモリ全然足りない | 36.4 |
| MiniMax-M3 (35.4) | △ カツカツ、KV + working で OOM 寄り | 35.4 |
| V4-Flash (31.1) | ✅ 128GB に 50GB の余裕、11.8 tok/s 実測 | 31.1 |
| Kimi K2.6 (30.3) | ❌ 256GB+ 必要 | 30.3 |
| Gemma 4 31B (14.4) | ✅ 動くが知能が大きく劣る | 14.4 |
つまり 「自宅 50 万円台で実用的に動かせる OW のうち、Agentic Index が一番高いのは V4-Flash」 という構造だ。31.1 という数値だけ見ると 4 位だが、「上 3 モデルは自宅で動かない」という条件をかけた瞬間、V4-Flash が 実質トップ に繰り上がる。
これがいまの個人開発者が直面している現実の選択肢で、ちょうど良いコスパポイントが V4-Flash に集中している。
3. MiniMax-M3 と V4-Flash、何が分かれ目になるか
ちなみに 3 位の MiniMax-M3 (428B / 23B active、2026 年 6 月公開) は、Agentic Index は V4-Flash より +4.3 高い。コーディングベンチ (SWE-Bench Pro 59.0%) では GPT-5.5 / Gemini 3.1 Pro を上回るとされ、評価としては明らかに強い。
ただ自宅構成の話になると分かれ目はクリアで、
- 総パラメータ 428B vs 284B → IQ2 で 110 GiB vs 74 GiB
- active 23B vs 13B → 1 token あたり CPU で計算する量が 1.8 倍
- 128GB RAM の場合: M3 は KV cache + working buffer を含めると OOM ぎりぎりアウト、V4-Flash は 50GB 級の余裕
M3 を自宅で快適に動かすには RAM 192GB or 256GB に上げる必要がある。32GB×4 (= 6 万円) でやめてる構成だとここの壁にぶつかる。RAM スロット数の制約 (4 スロット mobo) や 32GB→64GB DIMM の価格差を考えると、追加投資が +5-10 万円かかる計算だ。
つまり 「128GB RAM のラインを引いたとき、その線をギリギリで踏み切れる OW」が V4-Flash。M3 はラインの少し向こう側にいる。RAM 価格高騰の今、この差は 5-10 万円どころか 追加 10-15 万円 のメモリ投資差になって跳ね返ってくる。
これは「コスパ最強」という言葉が成立する稀なケースで、知能スコアが頭打ちで横並びになりつつある中、メモリフットプリントだけが鋭く差別化された結果だ。
4. 「16 コアが唸る」とはどういうことか
MoE モデルの推論は、伝統的な dense モデルとは挙動が違う。
DeepSeek-V4-Flash は 284B のパラメータを持つが、1 トークン推論するために実際に使う重みは 13B 分だけ。全 256 個ある expert のうち、6 個が選ばれて計算される。残り 250 個は今のトークンには無関係なので、メモリに「置いてあるだけ」でいい。
ここに「重みを GPU に置くか、CPU 側の RAM に置くか」という戦略分岐がある。
- 全部 GPU に置く: VRAM 74 GiB 必要。RTX PRO 6000 (96GB) なら乗る。普通の RTX 5090 (32GB) では絶対に無理。
- expert だけ CPU の RAM に置く (
-cmoe経路): VRAM は 7 GiB だけで済む。普通の RTX 5070 級 (16GB) でも attention 部分は乗る。代わりに RAM が 128GB 必要で、1 トークンごとに 13B 分の expert weight を CPU で計算する。
この後者の構成を選ぶと、推論時に CPU の全コアが本気で働き出す。llama-server の -t 16 で 16 スレッド全部を expert 計算に投入する。これが、私が今朝見た「16 コアが 100% 張り付き」の正体だった。
「CPU が主役になる時代が戻ってきた」と一瞬思ったが、実態はもう少し冷静で、GPU と CPU が役割分担する時代になった、というのが正確な表現だろう。
5. ハードウェア構成と再現コスト
このマシンの実構成と、それを「最小限の準フロンティア LLM ハコ」として再現する場合のコストを並べておく。
| 項目 | 実機 (うちの構成) | 最小再現構成 | 2026-06 想定コスト |
|---|---|---|---|
| GPU | RTX PRO 6000 BW Max-Q (96GB) | RTX 5070 (16GB) で十分 | 約 10 万円 |
| メモリ | 32GB × 4 = 128 GB | 32GB × 4 = 128 GB | 約 22-30 万円 ← 高騰中 |
| CPU | Ryzen 9 (16 core) | Ryzen 9 7900X (12 core) ~ | 約 8 万円 |
| マザボ + 電源 + SSD + ケース | (省略) | 一式 | 約 5 万円 |
| 合計 | 約 45-55 万円 |
正直、この記事を書き始めた最初は「30 万円で組める」と試算していた。だが 2026 年に入ってからの DDR5 高騰で内訳が大きく崩れた。詳しくは次の章で書くが、32GB DDR5 1 枚で $375 (約 5.5 万円)、1 年前の $80-120 から 400% 上がっている (Tom's Hardware, 2026-06)。
それでも、**「RTX PRO 6000 級 (100 万円超) のごつい GPU を買わなくても、合計 50 万円台で準フロンティア OW を自宅で動かせる」**という構造そのものは生きている。むしろ MoE 時代になって 支出のメインが GPU から RAM に移った、という新しい現実が見えてきた。
ここで重要な観察がある。
6. フル GPU vs CPU offload の速度差は 意外と小さい
今回ベンチマークで取った数値を並べる。同じ DeepSeek-V4-Flash IQ2_XXS-XL GGUF、同じプロンプト (フィボナッチ生成タスク、~800 token 生成) を、構成を変えて測った。
| 構成 | VRAM | RAM 使用 | gen tok/s |
|---|---|---|---|
| フル GPU (GPU0 単独, KV fp16) | 76 GiB | 16 GiB | 20.0 ← 最速 |
| フル GPU (multi-GPU split) | 76 + 11 GiB | 16 GiB | 13.6 (PCIe overhead) |
| フル GPU (KV q8_0) | 76 GiB | 16 GiB | 16.3 (逆効果) |
CPU MoE (-cmoe) | 7 GiB | 76 GiB | 11.8 ← 普及帯狙い |
ここで強調したいのは 「20 tok/s vs 12 tok/s」の差が想像より小さいことだ。
DeepSeek-V4-Flash の IQ2 量子化は 74 GiB。RTX PRO 6000 (96 GB VRAM) なら丸ごと乗るので VRAM 帯域 1700 GB/s を使い切れる。理論最大は ~430 tok/s。
なのに実測は 20 tok/s = 理論の 5%。なぜか。
答えは「llama.cpp の cchuter fork は WIP」だから。DeepSeek-V4 は MLA / CSA / HCA / Lightning Indexer / Hyper-connection / Gated Delta Net など多くの独自オペレータを持っていて、これらの CUDA kernel が最適化されていない。DeepSeek 公式の inference スタック (FlashMLA + DeepEP + DeepGEMM) なら桁違いの速度が出るが、サードパーティの llama.cpp はまだ「動かす」段階で、「速くする」段階に届いていない。
つまり、GPU の本来の力が引き出されていないので、CPU offload との差が縮んでいる。
これは「時間が解決する問題」だ。
llama.cpp の cchuter fork が upstream にマージされて、CUDA kernel がチューニングされれば、フル GPU は 50-100 tok/s 級に伸びる可能性が高い。だが CPU offload も IQ2 dequant kernel やキャッシュ局所性の最適化で +50% は望める。最終的な比率がどうなるかはわからない。
しかし 「現時点では 20 tok/s と 12 tok/s で勝負しているので、ごつい GPU を買う差別化要因が薄い」というのが、いま個人開発者にとっての現実だ。
7. なぜ MoE 時代に CPU+RAM が「復権」したのか
dense モデル (Llama 3 70B 等) 時代は、推論時に全 70B の重みを毎ステップ読み込む。これは メモリ帯域がボトルネックで、GPU の HBM3e (3-5 TB/s) でないと話にならなかった。CPU の DDR5 帯域は ~100 GB/s と 30-50 倍遅い。
MoE 時代になると話が変わる。
- DeepSeek-V4-Flash は 284B total だが、active は 13B
- 1 token = 13B 分のメモリアクセス
- CPU の DDR5 で 13B × 2 bpw (IQ2) = ~3 GB/token
理論上 100 GB/s / 3 GB = 33 token/s 出せるはず。実測 11.8 tok/s だが、これは CPU の actual 計算量 (dequant + matmul) も乗るから。それでもオーダーは合っている。
つまり MoE は「メモリ帯域要求を 1/20 に減らす」発明だった、と言ってもいい。これで CPU と GPU の差が、桁の差から 2-3 倍の差に縮まる。
だが、ここで皮肉な現実がある。
128GB RAM は、いま「6 万円」では買えない。
32GB DDR5-5600 × 4 ≒ 22-30 万円 (2026-06 時点)
1 年前なら $80-120/32GB ≒ 4 万円で 128GB が組めた。それが 2026 年に入ってからの AI / サーバー需要急増で DDR5 価格が 400% 上昇、現在は 32GB 1 枚で $375 (約 5.5 万円)、4 枚で 22-30 万円という水準になっている。緩和の見通しは 2027-2028 までないというのが業界の合意 (Tom's Hardware、TechTimes)。
つまり「MoE で CPU+RAM が GPU に競合できるようになった瞬間、AI 需要が今度は RAM 価格を吊り上げた」という構造になっている。
ただし、見方を変えるとこれはむしろ 「MoE 推論用途においてメモリは GPU 級の投資価値がある」と市場が認めた結果でもある。「メモリだけで RTX 5070 Ti 2 枚分」という支出は、3 年前なら馬鹿げていた。MoE 時代の今は、それが個人にとっても合理的な選択になりつつある。
支出のメインを GPU から RAM に移す — これが MoE 時代の hw 投資の新しい優先順位だ。
8. 何に使えるか
11.8 tok/s で 256K context は遅い。GPT-5 / Claude Opus 系の 80-150 tok/s と比べると 1/8 以下だ。リアルタイム対話には使えない。
ただ、用途を選べば実用に乗る。
lightning fast でなくてもいい用途:
- TRPG / 小説モード: 物語を進める backend として、思考に 30-90 秒待たされても許容。むしろ「考えてる感」が雰囲気として機能する。256K context があれば、世界観・登場人物・履歴を全部丸ごと持たせられる
- ReAct エージェント: 1 ステップ 100-300 token なら 5-15 秒で済む。tool 呼び出しのループ 5 ステップで 1 分。普通の ReAct なら許容範囲
- 長文要約・分析: 入力 32K の文書を一括で要約させる用途。1 分待たされても結果が良ければ問題ない
向かない用途:
- リアルタイム会話 (TTFB 5-30 秒)
- バッチコード生成 (1 ファイル 30 分待つくらいなら GPT-5 で 1 分の方が安い)
- 速応性のあるツール (検索クエリ補完など)
つまり「latency-tolerant な高度推論を、自分のマシンで API コストゼロで回せる」のが価値だ。プライバシー要件があるユースケース (相談・カウンセリング・社内文書解析) でも自前 LLM の強みが立つ。
9. DeepSeek の「難しさを輸出する」戦略
おまけに技術的に面白い観察を 1 つ。
DeepSeek が毎リリース (V2 → V3 → V3.2 → V4) で出してくるアーキは、論文と重みを OW で公開しつつ、内部 inference は 自社最適化 kernel (FlashMLA / DeepEP / DeepGEMM) で運用されている。サードパーティが追随するのに毎回 3-6 ヶ月かかる。
これは「速度が要る人はクラウド API で買ってね、知能だけ欲しい人は OW で持って行っていいよ」という収益モデルを アーキ設計レベルで強制している、とも読める。
V4 の Lightning Indexer / Hyper-connection / Gated Delta Net などの新規 op は、いずれも論文上は美しい設計だが、CUDA kernel として最適化するのは骨が折れる。サードパーティが「動かす」だけで精一杯になり、「速くする」までたどり着いた頃には DeepSeek は V5 を出している、というサイクル。
「論文と重みは公開、最適化された kernel は売る」という DeepSeek のモデルは、Anthropic / OpenAI とは違う形で持続可能性を確保している。個人開発者として、この設計思想は学びが多い。
10. 公開した: kotonia.ai の AI チャット / Creative Studio で V4-Flash を WIP 選択肢に
最後に。今回の実験は kotonia.ai の本番に WIP 公開した。
/chat/code (Code チャット) と /chat/studio (Creative Studio) の モデル選択で「DeepSeek V4 Flash (Local, $0, ~5-12 tok/s, WIP)」を選べるようにした。Cloudflare Tunnel 経由でユーザーが選択すると、私のマシンの 16 コアが本気で唸り始める仕組みだ。
speed は妥協済みなので、現状は「遅くても準フロンティア OW を試したい」層向けの選択肢に留めている。llama.cpp の V4 サポートが upstream にマージされて CUDA kernel がチューニングされ次第、ここの速度は伸びるはず。
「時間が解決する問題」の前にとりあえず動くものを置いて、ユーザーに 触れる選択肢 にしておく。これは個人開発者ができる、フロンティア OW への現実的な貢献だと思う。
おわりに
「50 万円で準フロンティア OW を自宅で動かす」という命題は、3 年前なら 「無理」 だった。それが MoE アーキの普及と、llama.cpp 系 OSS の頑張りで、現実になった。DDR5 高騰で『30 万円』にはならなかったのが少し悔しいが、それでも「動く」と「動かない」の境界線を越えるという意味では、十分にインパクトのある変化だ。
完璧な速度はまだ出ない。だが「動く」と「動かない」の差は、「速い」と「遅い」の差より遥かに大きい。
そして、自分の 16 コアが久しぶりに全力で唸っているシステムモニターを見ると、「投資が思わぬところで実を結んだ」という気分になる。GPU を主役で買ったマシンが、MoE 時代の到来で CPU と RAM の出番を作ってくれた、というのは個人開発者にとって気分のいい話だ。
買ったときの理由とは違う形で、ハードウェアが活躍する瞬間がある。