
I looked at my system monitor, and all 16 CPU cores were pinned near 100%. It had been a while since I'd seen that.
Normally on my workstation (RTX PRO 6000 Blackwell Max-Q + RTX PRO 4000 BW + 16 cores / 128GB RAM), the CPU never roars like this. Image gen, video gen, TTS — everything has been offloaded to the GPU. The CPU does I/O orchestration and preprocessing, nothing more.
Then I fired up DeepSeek-V4-Flash and every core jumped to full load. "CPUs are back in a GPU-centric world" — that small jolt of dissonance is where this article starts.
1. What I was actually doing
This morning I rebooted the machine after bumping RAM to 128GB. "With 128GB I should be able to push most of V4-Flash's experts onto CPU offload" — that's the hunch that got me to try.
DeepSeek-V4-Flash, released April 2026, is an OW Mixture-of-Experts model: 284B total / 13B active, 1M context, MIT. It sits with GLM-5.2 (~750B/40B active) and Kimi K2.6 (1T/32B active) among the current OW-frontier candidates.
The cloud API is $0.14/M input — productized normally. But running this class of model at home is a different story.
| Model | total / active | IQ2_XXS GGUF | Runs at home? |
|---|---|---|---|
| DeepSeek-V4-Flash | 284B / 13B | ~73 GiB | Yes ← today |
| GLM-5.2 | ~750B / 40B | ~239 GiB | No (256GB RAM minimum) |
| Kimi K2.6 (INT4 native) | 1T / 32B | ~250 GiB | Same |
| Qwen3-235B-A22B | 235B / 22B | ~70 GiB | Yes, but dumber than V4-Flash |
In short, 284B / 13B active is roughly the ceiling of "OW intelligence that fits on a personal machine". Anything bigger demands a 256GB RAM investment.
2. The Agentic Index makes V4-Flash's unique position pop
Here's the latest Artificial Analysis Agentic Index (mean of GDPval-AA v2 + τ³-Banking) for OW models.
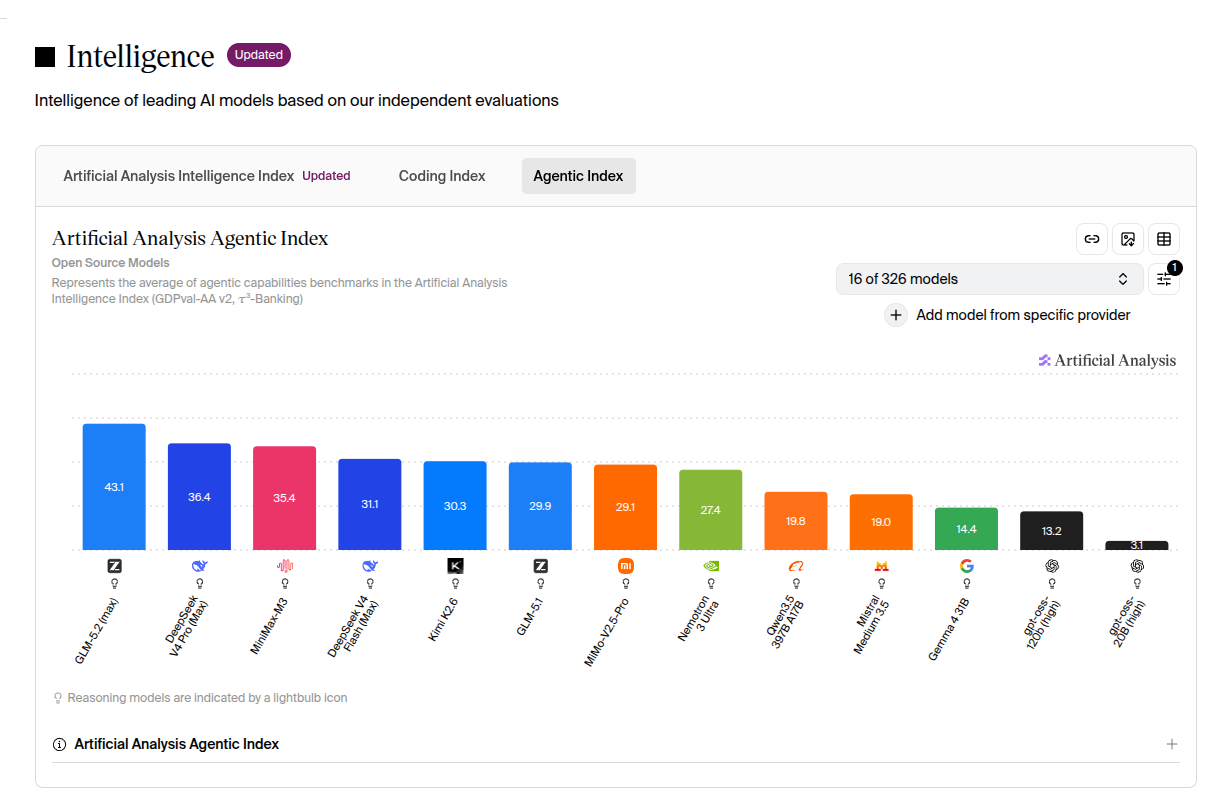
The raw numbers:
| Rank | Model | Agentic Index | total / active | IQ2 GGUF |
|---|---|---|---|---|
| 1 | GLM-5.2 (max) | 43.1 | ~750B / 40B | ~239 GiB |
| 2 | DeepSeek V4-Pro (Max) | 36.4 | 1.6T / 49B | ~430 GiB |
| 3 | MiniMax-M3 | 35.4 | 428B / 23B | ~110 GiB |
| 4 | DeepSeek V4-Flash (Max) | 31.1 | 284B / 13B | ~74 GiB ★ |
| 5 | Kimi K2.6 | 30.3 | 1T / 32B native INT4 | ~250 GiB |
| 6 | GLM-5.1 | 29.9 | (older gen) | — |
| 7 | MiMo-V2.5-Pro | 29.1 | — | — |
| 8 | Nemotron 3 Ultra | 27.4 | — | — |
| 9 | Qwen3.5 397B A17B | 19.8 | 397B / 17B | ~100 GiB |
| 10 | Mistral Medium 3.5 | 19.0 | — | — |
| 11 | Gemma 4 31B | 14.4 | 31B dense | ~20 GiB |
| 12 | gpt-oss 120b (high) | 13.2 | 120B / 5.1B | ~30 GiB |
Now overlay the constraint "can a home 128GB RAM build (currently in the ~$3-4K range thanks to the DDR5 spike, detailed later) actually run this at usable speed (≥10 tok/s)?", and the picture flips:
| Model | Runs at home on 128GB RAM? | Agentic Index |
|---|---|---|
| GLM-5.2 (43.1) | ❌ swap-thrashes at 1-3 tok/s | 43.1 |
| V4-Pro (36.4) | ❌ nowhere near enough memory | 36.4 |
| MiniMax-M3 (35.4) | △ on the edge — KV + working buffer pushes it to OOM | 35.4 |
| V4-Flash (31.1) | ✅ leaves 50GB of headroom on 128GB, measured 11.8 tok/s | 31.1 |
| Kimi K2.6 (30.3) | ❌ needs 256GB+ | 30.3 |
| Gemma 4 31B (14.4) | ✅ runs, but the intelligence gap is huge | 14.4 |
So "of the OW models that actually run at home in the $3-4K range, the one with the highest Agentic Index is V4-Flash". Looking at 31.1 alone it's 4th place; once you apply the constraint "the three above don't fit at home", V4-Flash effectively jumps to the top.
That's the real decision matrix indie developers face right now, and the sweet spot lands squarely on V4-Flash.
3. MiniMax-M3 vs V4-Flash, where the line falls
Worth a deeper look at 3rd-place MiniMax-M3 (428B / 23B active, released June 2026). Its Agentic Index is 4.3 points higher than V4-Flash. On coding benches (SWE-Bench Pro 59.0%) it beats GPT-5.5 / Gemini 3.1 Pro. As a pure model evaluation, M3 is clearly stronger.
But on the home-rig question the gap is crisp:
- Total params 428B vs 284B → IQ2 110 GiB vs 74 GiB
- Active 23B vs 13B → per-token CPU compute 1.8× heavier
- On 128GB RAM: M3 plus KV cache plus working buffer just barely OOMs, V4-Flash leaves ~50GB headroom
To comfortably run M3 at home you need 192GB or 256GB of RAM. In 2024 that was a $700-900 add-on. In June 2026 it's another $1,500+ of memory on top of an already-spiked baseline. The wall just got taller.
So "the OW model that crosses the 128GB-RAM line by a hair is V4-Flash". M3 is on the other side of that line, and DDR5 pricing makes the gap painful.
This is one of those rare situations where the phrase "best bang-for-buck" cleanly applies — with intelligence scores converging at the top, memory footprint becomes the sharpest differentiator left.
4. What "16 cores roaring" actually means
MoE inference behaves differently from classic dense models.
DeepSeek-V4-Flash has 284B parameters, but for any single token it actually uses about 13B worth of weights. Of the 256 experts, 6 are selected and computed; the other 250 are irrelevant for this token — they just sit in memory.
That creates a strategic choice: "do you put the weights on the GPU, or in CPU-side RAM?"
- All on GPU: needs 74 GiB of VRAM. RTX PRO 6000 (96GB) fits it. A normal RTX 5090 (32GB) cannot.
- Experts in CPU RAM (the
-cmoepath): VRAM drops to ~7 GiB. A common RTX 5070-class (16GB) is enough for the attention path. The cost: you need 128GB of RAM, and every token gets its 13B of expert weight crunched on the CPU.
Pick the second route and the CPU's full core count goes to work on inference. llama-server -t 16 puts all 16 threads onto expert compute. That's what I was watching this morning — 16 cores pinned at 100%.
"CPUs are taking the lead again" was my first reaction, but the calmer reading is: GPU and CPU are sharing the work now.
5. Hardware build and reproduction cost
Here's the rig I'm actually running, and what the minimum "near-frontier-LLM box" looks like as a build.
| Part | My rig | Minimum reproduction | Est. cost (2026-06) |
|---|---|---|---|
| GPU | RTX PRO 6000 BW Max-Q (96GB) | RTX 5070 (16GB) is enough | ~$650 |
| RAM | 32GB × 4 = 128 GB | 32GB × 4 = 128 GB | ~$1,500-2,000 ← spiked |
| CPU | Ryzen 9 (16 cores) | Ryzen 9 7900X (12 cores) is fine | ~$550 |
| Mobo + PSU + SSD + case | (skip) | full set | ~$350 |
| Total | ≈ $3,000-3,600 |
Honestly, when I started writing this article I'd budgeted $2K for the build. The 2026 DDR5 shortage wrecked that estimate. Details in the next section, but in short: 32GB DDR5 is $375/stick (~5.5万円), 400% above what it cost a year ago (Tom's Hardware, 2026-06).
Even so, the structural claim survives: "you don't need a $10K-class GPU like the RTX PRO 6000 — a $3K-class build runs a near-frontier OW model at home". What changed is that the main expense migrated from the GPU to the RAM, which is a story all on its own about the MoE era.
There's an important observation lurking here.
6. Full-GPU vs CPU-offload speed gap is smaller than you'd guess
The numbers I measured today, same DeepSeek-V4-Flash IQ2_XXS-XL GGUF, same prompt (Fibonacci task, ~800 generated tokens), varying only the topology.
| Topology | VRAM | RAM used | gen tok/s |
|---|---|---|---|
| Full GPU (GPU0 only, KV fp16) | 76 GiB | 16 GiB | 20.0 ← fastest |
| Full GPU (multi-GPU split) | 76 + 11 GiB | 16 GiB | 13.6 (PCIe split overhead) |
| Full GPU (KV q8_0) | 76 GiB | 16 GiB | 16.3 (worse, ironically) |
CPU MoE (-cmoe) | 7 GiB | 76 GiB | 11.8 ← consumer-build target |
The thing worth emphasizing is "20 tok/s vs 12 tok/s" is a much smaller gap than you'd expect.
V4-Flash IQ2 quant is 74 GiB. On an RTX PRO 6000 (96 GB VRAM) it fits whole, so you get full VRAM bandwidth of ~1700 GB/s. Theoretical ceiling: ~430 tok/s.
Yet measured is 20 tok/s = 5% of theoretical. Why?
Answer: llama.cpp's cchuter fork is WIP. V4 ships many novel operators — MLA / CSA / HCA / Lightning Indexer / Hyper-connection / Gated Delta Net — and none of them have tuned CUDA kernels yet. DeepSeek's in-house stack (FlashMLA + DeepEP + DeepGEMM) yields orders-of-magnitude better numbers, but third-party llama.cpp is still in "make it run" mode, not "make it fast" mode.
So the GPU isn't being asked for what it can really do, which shrinks the gap to CPU offload.
This is a "time will solve this" problem.
When the cchuter fork merges upstream and CUDA kernels get tuned, full GPU likely climbs to 50-100 tok/s. But CPU offload still has +50% headroom from IQ2 dequant kernels and cache-locality work. The final ratio is unknown.
What's true today: "20 tok/s vs 12 tok/s is the matchup, so there's not much reason to splurge on a heavy GPU yet" — that's the indie developer's reality.
7. Why MoE brought CPU+RAM back into the picture
In the dense-model era (Llama 3 70B etc.) every inference step read all 70B of weights. Memory bandwidth was the bottleneck, and you needed GPU HBM3e (3-5 TB/s) to be in the game. CPU DDR5 bandwidth (~100 GB/s) was 30-50× too slow.
MoE flips the script.
- V4-Flash is 284B total, but active is 13B
- 1 token = 13B worth of memory access
- CPU DDR5 with 13B × 2 bpw (IQ2) = ~3 GB/token
Theoretical: 100 GB/s ÷ 3 GB = 33 tokens/s should be achievable. Measured is 11.8 tok/s, because actual CPU compute (dequant + matmul) also costs, but the order of magnitude lines up.
In short, MoE is the invention that "cuts memory-bandwidth demand by ~20×". That collapses the CPU-vs-GPU gap from an order of magnitude to roughly 2-3×.
But here's the ironic twist.
128GB of RAM does not, in fact, "cost $420" anymore.
32GB DDR5-5600 × 4 ≈ $1,500-2,000 (June 2026)
A year ago $80-120 per 32GB stick was the norm, and you'd build 128GB for $400-500. Then the AI / server demand spike of 2026 lifted DDR5 prices by 400%. Today it's $375/stick and $1,500-2,000 for 128GB. Industry consensus is that relief won't arrive until 2027-2028 (Tom's Hardware, TechTimes).
So the pattern goes: "MoE makes CPU+RAM competitive with GPU → and then AI demand starts pulling RAM prices into the stratosphere too". Both ends of the stack get squeezed.
You can read it more positively, though: this is the market saying "for MoE inference, memory deserves GPU-tier capital allocation". "Two RTX 5070 Ti's worth of money, but it's all RAM" sounds insane three years ago. In the MoE era it starts to make rational sense even for individuals.
Shift the main expense from GPU to RAM. That's the new hierarchy of hardware investment for the MoE era.
8. What it's actually useful for
11.8 tok/s with 256K context is slow. Compared to GPT-5 / Claude Opus at 80-150 tok/s, this is 1/8 the speed. Realtime conversation is out.
But pick the use case carefully and it lands as usable.
Uses where "fast" is optional:
- TRPG / novel-mode backend: as the engine that drives a story, waiting 30-90 seconds on a thought is acceptable — even feels like "the model is thinking". 256K of context means the world-building, characters, and history all fit in one shot.
- ReAct agents: 100-300 tokens per step is 5-15 seconds. A 5-step tool-call loop is under a minute. Within tolerance for ordinary ReAct.
- Long-context summarization/analysis: feed a 32K document, get a summary in a minute. Trade-off works if output quality is solid.
Uses it doesn't fit:
- Realtime conversation (TTFB 5-30s)
- Batch code gen (if it takes 30 min per file, GPT-5 at 1 min is cheaper to use)
- Latency-sensitive tools (search autocomplete, etc.)
In other words, the value is running latency-tolerant high-quality reasoning on your own box, with zero API cost. Privacy-bound workloads (consulting, counseling, internal doc analysis) get extra mileage from owning the inference.
7-extra. DeepSeek's "export the difficulty" strategy
A technical aside that's worth a beat.
Every DeepSeek release (V2 → V3 → V3.2 → V4) ships novel architecture as OW weights and a paper, while the company's actual inference runs on proprietary kernels (FlashMLA / DeepEP / DeepGEMM). Third parties take 3-6 months to catch up each cycle.
You can read this as a business model enforced at the architecture level: "if you need throughput, buy our API; if you only need intelligence, take the weights home".
V4's Lightning Indexer / Hyper-connection / Gated Delta Net are beautiful on paper, but writing tuned CUDA kernels for them is real work. Third parties barely finish "make it run" before DeepSeek ships V5.
"Open the paper and weights, sell the optimized kernels" is a sustainability model distinct from Anthropic / OpenAI. As an indie dev, there's a lot to learn from this stance.
10. Shipped: V4-Flash is now a WIP model option in kotonia.ai's Code chat / Creative Studio
Wrapping up. Today's experiment got shipped to kotonia.ai production as a WIP option.
In the model selector on /chat/code (Code chat) and /chat/studio (Creative Studio), "DeepSeek V4 Flash (Local, $0, ~5-12 tok/s, WIP)" is now selectable. Pick it, and my workstation's 16 cores spin up via Cloudflare Tunnel.
Speed is the known trade-off, so right now this is positioned for users who want to try a near-frontier OW even slowly. Once llama.cpp's V4 support merges upstream and the CUDA kernels get tuned, this option will get faster.
Ship a working version of the thing the world has yet to solve, and let users actually touch it. That feels like a realistic contribution an indie developer can make to frontier OW.
Closing
"Run a near-frontier OW model at home for $3-4K" was impossible three years ago. The MoE shift and the open-source llama.cpp work made it real. DDR5 prices didn't cooperate by staying at the $2K target I'd hoped for, but crossing from "can't run it at all" to "runs slowly but runs" is a much larger jump than the difference between $2K and $4K builds.
The speed isn't perfect yet. But the gap between "runs at all" and "doesn't run" is far bigger than the gap between "fast" and "slow".
And when you watch your 16 cores roar in the system monitor, you get this little feeling of "the investment paid off in an unexpected direction". A box you built for the GPU is now being repaid by the CPU+RAM the MoE era pulled into the spotlight. For an indie developer, that's a satisfying way to close the loop.
Hardware shipped for one reason occasionally gets a second life elsewhere.