Kotonia Articles
Articles
Implementation notes and product updates about Kotonia voice AI, AI chat, image generation, and team collaboration.
 Latest
LatestI shipped Iris — an AI partner with a face and limbs — in one day. Meet kotonia-desktop.
A Tauri 2 desktop app where a silver-haired android sits in the corner, listens to your voice, runs bash on your machine, and reads the result back in her own voice while her face lip-syncs. Built in a day. A slightly cheeky hybrid cost model: ride competitors' loss-leader brain subscriptions, layer kotonia's near-unlimited voice/avatar on top.
#agent#tauri#voice
Automatic Transfer of T2I LoRA to the Edit Pathway in Unified VL Image Generation — A Controlled Evaluation on HiDream-O1
A controlled 240-sample evaluation on HiDream-O1-Image showing that LoRA adapters trained on T2I signal alone deliver commercial-grade quality on the image-to-image edit pathway. Structural property of unified VL architectures; absent in SDXL/FLUX dev siloed architectures.
#hidream#lora#image-generation
Letting the AI agent on my home GPU write code, from a phone on the train — one weekend wiring the kotonia-cli daemon to a web /agent console over WebSocket
I wired the kotonia.ai web UI to a kotonia-cli daemon living on my home PC, with WebSocket carrying tasks one way and event streams the other. Tap a prompt on the phone, the RTX 6000 Blackwell at home spins up a fresh worktree and runs ReAct, and bash output lands in the browser in real time. The technical guts: bridging a sync ApprovalHandler trait to async WebSockets, a Cookie-auth-shaped device-code login, and a SessionRegistry that auto-resumes from disk.
#agent#websocket#rust
The night I tried to build a specialized LoRA, ran headfirst into the collapse of legal NSFW datasets, and ended up inventing 3-stage captioning
Starting from the under-fit signal 'v1 nipple LoRA at @1.5 > @1.0', I structurally analyzed how legal NSFW dataset paths are closed off by CSAM contamination and DRM, then trained V2 LoRA using CivitAI RED + 3-stage captioning + informational value frame, confirming dramatic prompt adherence improvement and generalization preservation via A/B. A single-night research log.
#LoRA#image-generation#HiDream
An AI told me to stop writing tech articles, so I'm writing a tech article about that
I asked Claude Fable 5 to adversarially review my product and strategy. It didn't find holes in the tech — it found four holes in the business. A solo developer's playbook for using AI as a board-room counterparty, and what didn't happen with Opus-class models.
#ai#claude#indie
Avatar chat hits an emotional-bandwidth ceiling — and how 70s psychology became my indie moat
Voice avatars carry a strong first-time wow, but the screen 'converges' after 2-3 turns. Starting from the insight that lip-sync bandwidth ≠ emotion bandwidth, this is the design log of how I scaled expressivity to N × M without growing LLM context. Why borrow Ekman's FACS, why frontier labs won't ship this, and how far the indie moat actually reaches.
#avatar-chat#ux#indie-dev
I built a terminal-native creative agent in a day — for verbal thinkers who keep getting beaten up by visual-first tools
kotonia-cli, written in a day: bash as the only tool, image generation that returns in 3 seconds, native ffmpeg orchestration. The category gap that Claude Code and Codex never filled. The only place a solo dev can beat the frontier labs isn't model quality — it's lossless UX for verbal thinkers.
#agent#cli#indie-dev
The day my 16 cores finally roared — running a near-frontier OW model at home through the 2026 DDR5 price spike, MoE-era CPU+RAM revival
I tried running DeepSeek-V4-Flash (284B MoE / 13B active) on my home rig (RTX 6000 + 128GB RAM). The full-GPU vs CPU-offload speed gap was only 2x. You no longer need a $10K-class GPU like the RTX PRO 6000 to run near-frontier OW at home. With the 2026 DDR5 shortage, however, the build runs closer to $3.5K than the $2K I'd budgeted at the start — and 'RAM is now your GPU-tier expense' became the unexpected angle of this piece.
#llm#moe#deepseek
The Day a Solo Developer's Accumulated Assets Finally Started to Compound — When memory and git Stepped Into the "Being Used" Side via Agents
An implementation note: I built a pipeline that semantically compresses my own memory files and git history through an agent, then mechanically excavates new article seeds from them. I distilled the conditions for an individual developer's accumulated assets to start compounding into three structural pieces.
#ai#llm#agent
Why I Trained a LoRA for HiDream-O1-Image — The Unfiltered Story
The unfiltered story behind the HiDream-O1-Image LoRA: why anime quality is O1's weak spot, how 191 hand-picked images trained a visual booster, NSFW controllability, and what my analytics revealed about conversion drivers.
#lora#hidream#imagegen
Fighting Churn: The Day I Spent Entirely on Unglamorous Fixes
No new features — just plugging the silent leaks that drove new users away before they ever found the value. Here's what I found and fixed.
#webdev#ux#startup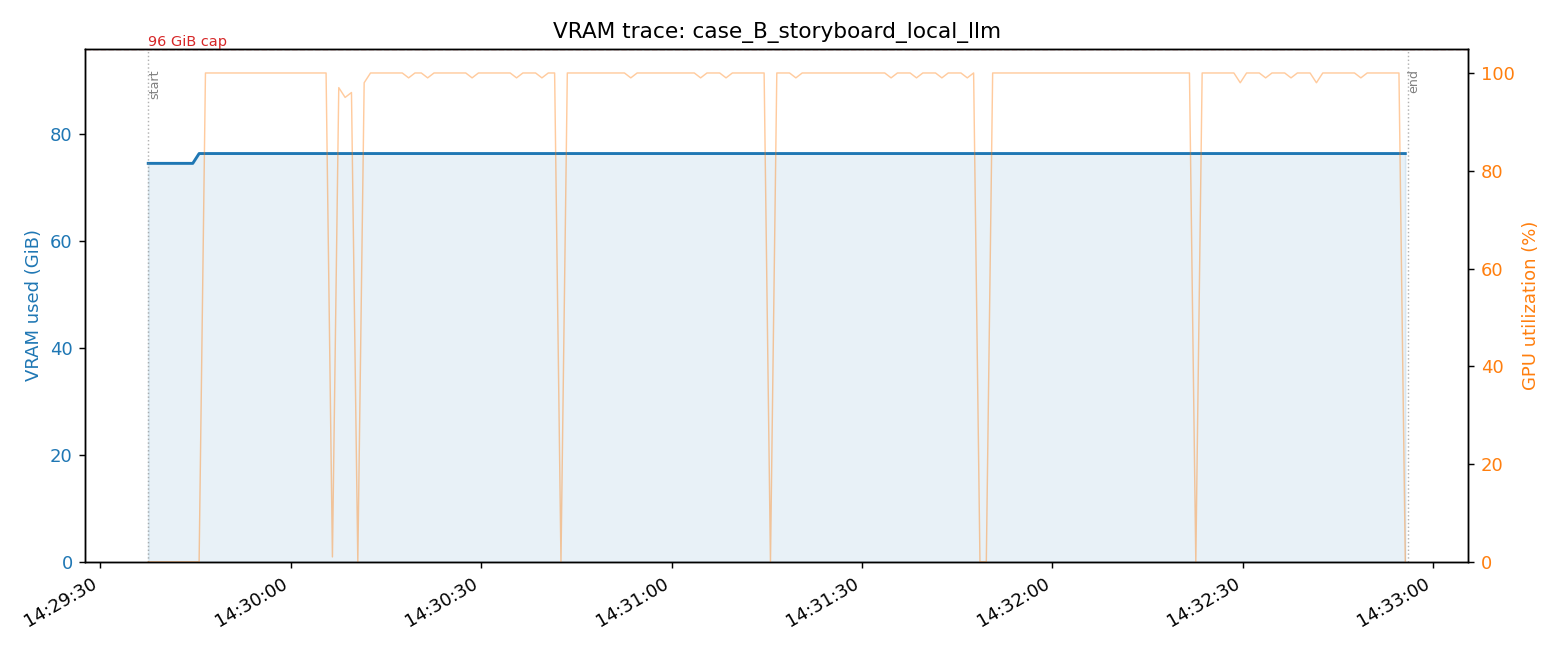
Five Years Later, I Finally Have 96GB VRAM — What It Actually Unlocks for Agent Loops
Not a GPU unboxing. A real look at what 96GB VRAM enables for multi-model agent pipelines — and where it still hits its limits.
#gpu#ai#machinelearning
Turning a 1-Line Idea Into a 40-Second Short with a 10-Beat Local Video Pipeline
Full pipeline: Gemma 4 31B expands a one-liner into a 10-beat script, HiDream generates images, LTX-2 I2V renders clips, and ffmpeg assembles everything — all on one local GPU in 25–30 min.
#python#ai#machinelearning
Running LTX-2.3 Alongside TTS on a Single 96GB GPU with a Cold-Start Architecture
How to go from 86 GiB idle VRAM (instant OOM) to 0 GiB idle / 40 GiB peak by using a cold-start design for LTX-2.3 on one RTX Pro 6000 Blackwell.
#gpu#python#machinelearning
Betting on the video niche the big labs walked away from — model A/B to making I2V the mainstay
Is there niche demand in free creation with the guardrails off? A solo dev on one local GPU: from model A/B to making high-res I2V the mainstay.
#solo-dev#generative-ai#video-generation
Building a Sarcastic AI English Tutor with Persona-as-Code and Gemini Audio Input for Pronunciation Correction
How I built a high-attitude AI English tutor using persona-as-code design, Qwen3-ASR for multilingual STT, and Gemini audio input for real pronunciation feedback — solo dev perspective.
#ai#webdev#typescript
Cutting LTX-2 22B Peak VRAM by 40% with fp8_cast — and Why optimum-quanto Was a Trap
How fp8_cast reduced LTX-2 22B peak VRAM from 40 GiB to 24 GiB in cold-start mode, and why optimum-quanto silently breaks the transformer.
#ai#machinelearning#gpu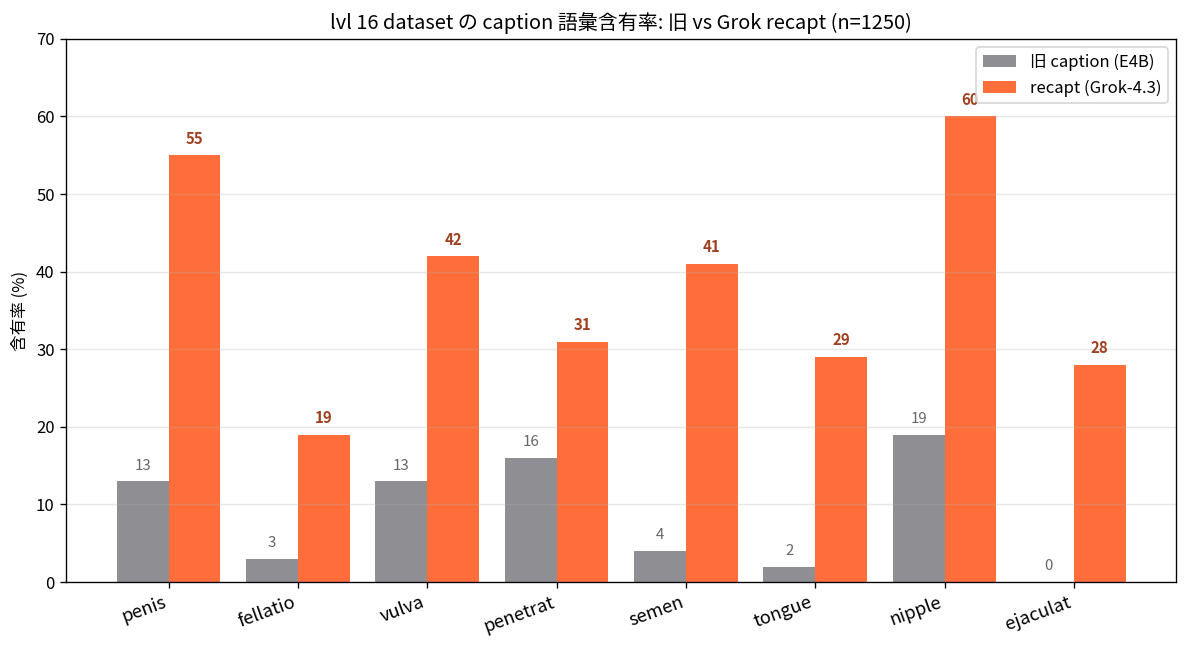
The real bottleneck was vocabulary, not the layer: unlocking hidden capability in HiDream-O1 via caption vocab repair
A research note on unlocking NSFW expressivity in HiDream-O1 (8B). The real bottleneck turned out to be the VLM captioner (E4B rounding "fellatio" into "oral sex"), not the model layers. Vocab repair via Grok-4.3 + two-stage prompts, then 8B full fine-tune at 54.6 GB resident on a single 96 GB GPU via bitsandbytes 8-bit Adam. Same-model / different-caption killshot included.
#HiDream-O1#fine-tuning#captioning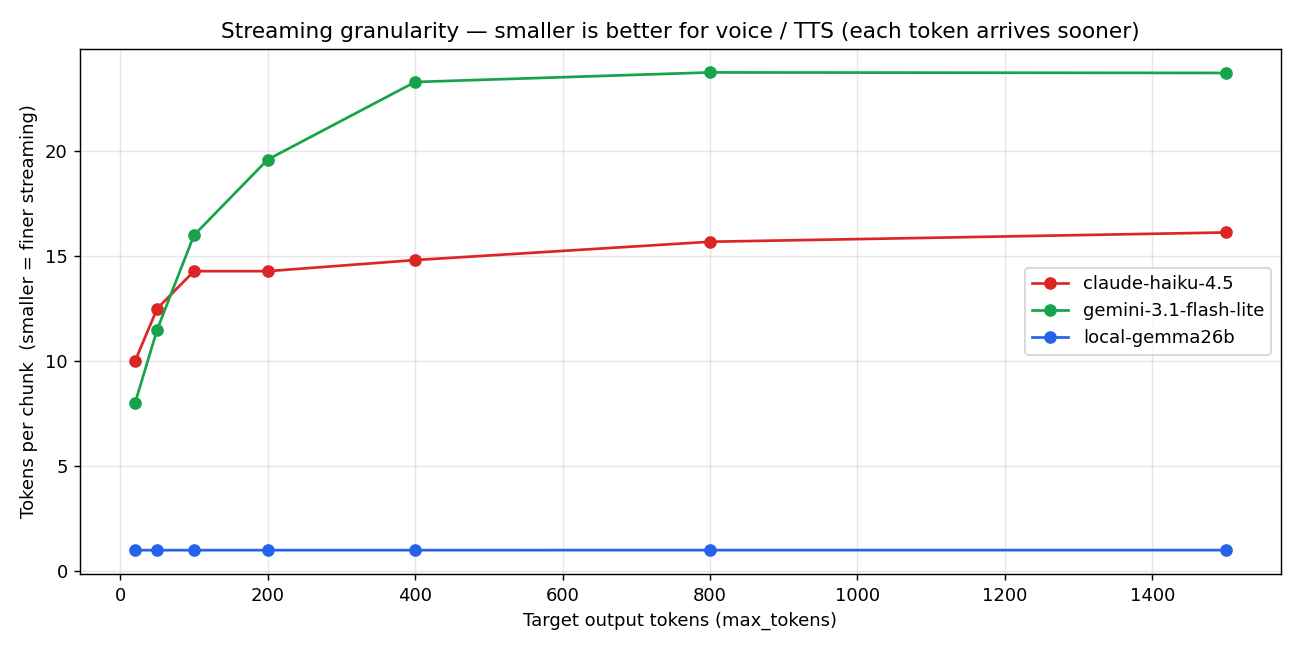
From 600ms to 22ms: I dumped frontier APIs and put a local LLM behind every avatar so my voice-first actually responds in under a second. A performance-tuning maniac's complete writeup
Claiming voice-first while accepting 700ms TTFB from a frontier API is a structural contradiction. Here is how I put Gemma 4 26B A4B Uncensored on a local GPU, dropped API spend to zero, cut TTFB by 30x, and unlocked uncensored output at the same time. 105 benchmark samples, 4 graphs, stress tests, the integration diff, and a breakdown of the resulting moat.
#voice-first#local-llm#gemma-4
Don't Trust an Agent's Self-Discipline — How Three Idea Mining Duplicates Slipped Past Prompt-Level Rules, and Tool-Layer Blocking Fixed It Structurally
I had to learn the hard way: even rules explicitly written into a prompt get broken by the agent. Three duplicate ideas slipped past my idea mining pipeline. The root cause, and the structural fix — baking TF-IDF dedup into the tool layer so the rule cannot be bypassed. The enforcement principle for agent design.
#ai#llm#agent
HiDream Raw Output Failed → Tried Dev-2604 → VRAM Math Killed It → Won with a Prompt Enhancer Instead
How we discovered that HiDream-O1's raw outputs collapse on plain Japanese prompts, tried switching to Dev-2604, found the VRAM math impossible, and won by adding a Gemini Flash Lite prompt enhancer instead. Four non-obvious HiDream pitfalls documented via A/B benchmarking.
#hidream#diffusion#promptengineering
HiDream Skeleton Mode: Prompt Beats OpenPose Ref — 8 Patterns Benchmarked
Benchmarking HiDream-O1-Image skeleton mode across 8 patterns reveals 3 counterintuitive findings about openpose refs, resolution drops, and shift values.
#ai#python#machinelearning
Implementing Claude Code's Memory Model as a Dreaming Layer on 58 Articles
I broke down why Claude Code's memory works, and applied it to my own 58-article tech blog. Implementation notes on the full path raw articles → semantic index → TF-IDF dedup → chunked draft, on local Gemma 4 26B driven through Codex CLI.
#llm#agent#tfidf
Replicating a Language-Learning Comedy Short with Claude Code — Gemini as a Multimodal Sub-Agent
Building a local GPU + Gemini 3.1 Pro hybrid pipeline that generates publishable comedy Shorts from a single line of text in under 60 seconds.
#ai#python#machinelearning
HiDream-O1-Image 3–8x Faster: Benchmarking Steps, CFG, and Resolution
Real-world timing benchmarks for HiDream-O1-Image Full — tuning steps, guidance scale, and resolution to speed up iteration without killing quality.
#ai#machinelearning#gpu
If you call your product voice-first, don't put a 'Start Recording' button in the middle of the screen
My AI character chat app billed itself as voice-first, yet a giant mic button sat dead-center at the bottom of the mobile screen. A CSS bug report became a product-philosophy reckoning.
#ux#indie#mobile
When the Features Were There All Along — How a UI Split Saved My Solo SaaS's Onboarding
A first-party analytics post-mortem: video generation drives signups but day-one churn was brutal. The video-gen know-how was already in our ReAct agent, but nobody could find it. Here is how a UI split unlocked it.
#solo-dev#UX#AI