From 600ms to 22ms: I dumped frontier APIs and put a local LLM behind every avatar so my voice-first actually responds in under a second. A performance-tuning maniac's complete writeup
I cut LLM short-message TTFB from 600ms down to 22ms.
My avatar (a Ditto-driven lip-synced talking head) now starts replying inside one second after the user stops talking. Not running on GPT-5 or Claude or Gemini — running on a local LLM on my own GPU. API spend went to zero. The structural ceiling that kept "voice-first" from being real has been lifted.
This is the whole writeup.
1. The argument you can't skip before claiming "voice-first"
A while back I wrote a piece arguing that if you call your product voice-first, you don't put a "Start Recording" button in the center of the screen. Voice-first is a UI proportion claim, not a tech-stack claim.
There's a sequel to that argument. Even if your UI is voice-first, the moment your LLM makes the user wait 700ms, your product is not voice-first.
In natural human conversation, the gap between "you stop talking" and "the other person starts replying" is around 300-500ms. At 900ms, the other side notices "they're thinking." At 1.5s it becomes "awkward silence."
The frontier API reality:
- Claude Haiku 4.5: TTFB median ~744ms, p90 of 4104ms
- Gemini 3.1 Flash-Lite Preview: TTFB ~537ms
- GPT-5 family: roughly the same band
That's just the LLM's contribution to first-byte. On top of that you have STT (~50ms with faster-whisper), TTS first chunk (~60ms with Qwen3-TTS), Ditto avatar bring-up, and network round-trips.
Total perceived latency lands around 1.5-2 seconds. Too slow to call voice-first. The 900ms wall doesn't break.
And the killer is the p90 number. Users remember the slow moments more than the fast ones. "Sometimes goes silent for 4 seconds" is the single biggest churn driver for a voice product.
The only way to fix this structurally is to drop the API and host the LLM yourself.
2. Why Gemma 4 26B A4B Uncensored, specifically
When I decided to switch to local, I set four selection criteria:
- MoE (Mixture of Experts) — even if total params are large, low active params means faster inference
- Quantizable to fp8 — needs to co-resident with other services on an RTX PRO 6000 Blackwell Max-Q (96GB)
- Native multimodal (vision at minimum) — text-only is a non-starter when image captioning and studio integration are on the roadmap
- An uncensored variant must exist publicly — guardrails get in the way for character chat (a "mesugaki" English tutor persona doesn't survive frontier safety filters), and NSFW captioning (which I need for my LoRA training pipeline) requires guard-off to surface the right vocabulary
Only one stack hits all four cleanly: Gemma 4 26B A4B Uncensored (Apache 2.0, multiple uncensored variants by prithivMLmods / TrevorJS / others).
- 25.2B total params, 3.8B active in MoE → inference speed in the 4B-dense neighborhood
- 52GB at bf16, ~28GB resident after fp8 cast
- Native multimodal: text + vision + audio + video
- Multiple uncensored variants already published (abliteration / ARA techniques)
- 256K context, Apache 2.0
I stood it up on vLLM. --quantization fp8, --gpu-memory-utilization 0.40, --max-model-len 32768, --enable-auto-tool-choice --tool-call-parser gemma4.
GPU 0 (6000 BW, 96GB) already had HiDream (fp8 ~9GB resident) and LTX-2 (cold-start, peak ~24GB) on it. Dropped Qwen3-TTS Base (low utilization) and moved the new LLM into that slot.
Resident: +39GB (fp8 weights + 32k KV cache + scratch). Even at LTX-2 peak it's 30GB to spare. Coexistence verified.
3. The raw numbers — what the bench actually shows
I took 105 samples across three providers (Local Gemma 4 26B fp8 / Claude Haiku 4.5 / Gemini 3.1 Flash-Lite Preview), varying output length at 20 / 50 / 100 / 200 / 400 / 800 / 1500 tokens.
3.1 TTFB — Time to First Byte
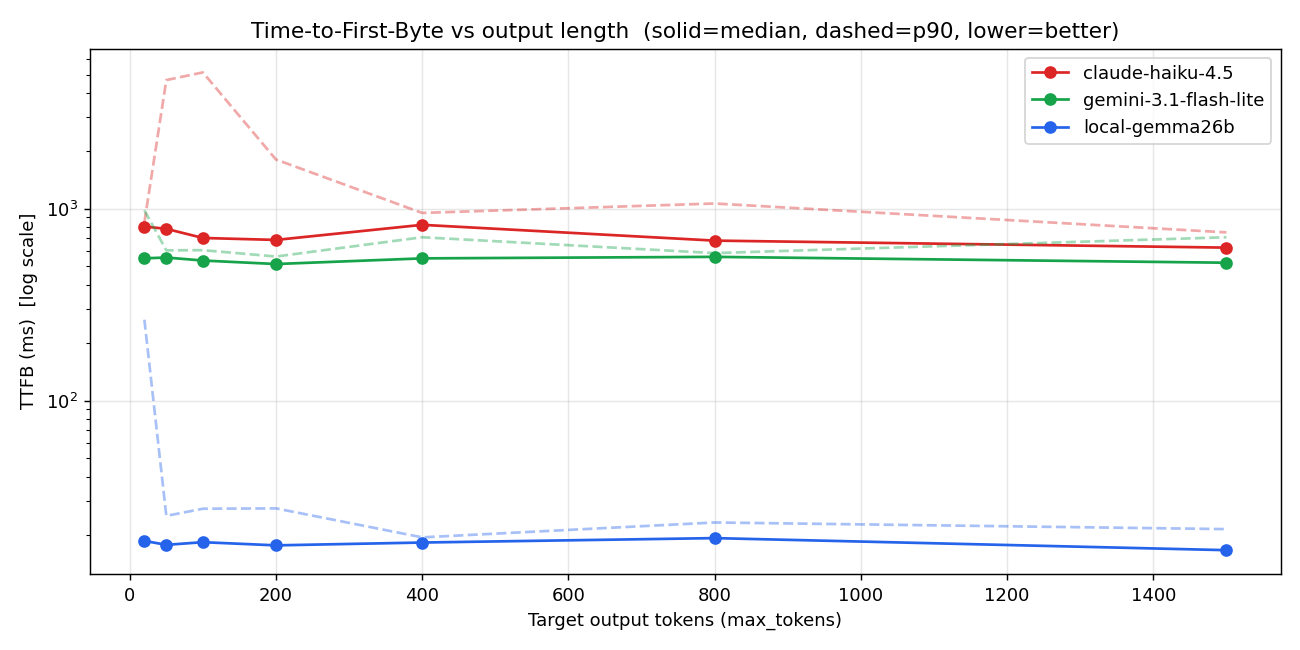
Y-axis is log scale. Local (blue) is flat at 17-25ms across every output length. The APIs are flat at 530-820ms.
p90 is even more brutal:
- Local p90: 25ms
- Gemini Flash-Lite p90: 601ms
- Haiku p90: 4104ms (5.5× the median) ← this one's actually scary
Haiku's median is 744ms, but one out of every ten calls is over 4 seconds. In a voice production setup, that translates to "intermittent unexplained 4-second silences." Users notice. They leave.
3.2 Pure TPS (actual generation speed)
The standard TPS metric (out_tokens / wall_clock) includes TTFB and trailing chunks, which underestimates the generation rate for short outputs. Computing instead (out_tokens - 1) / (t_last_content - t_first_content) strips out TTFB and trailing usage chunks, giving pure generation rate.
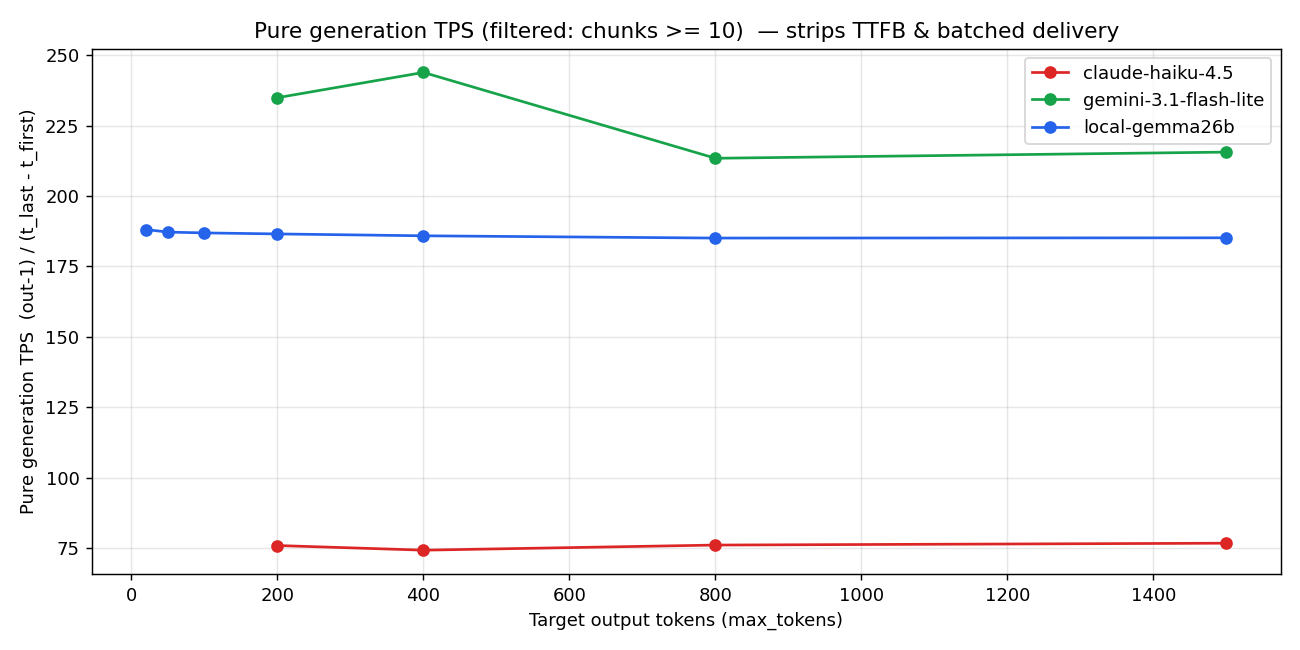
In pure generation rate, Gemini Flash-Lite wins at 215-244 tok/s, Local is 185 tok/s, Haiku is 76 tok/s.
Reading just this chart, you might think "Gemini is actually the winner." But this isn't the voice-chat story. Here comes the real one.
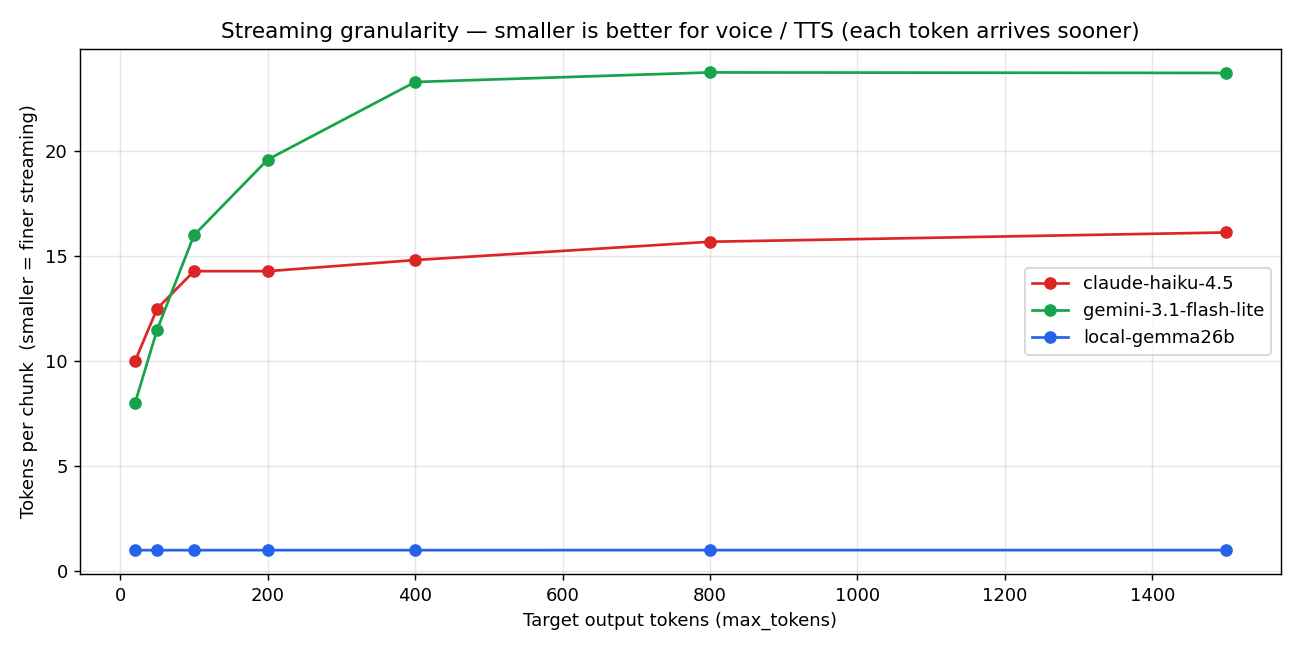
3.3 ★ Streaming granularity — the metric that decides voice UX
This is the indicator I'm most glad I found this round: how many tokens are packed into each streaming chunk.
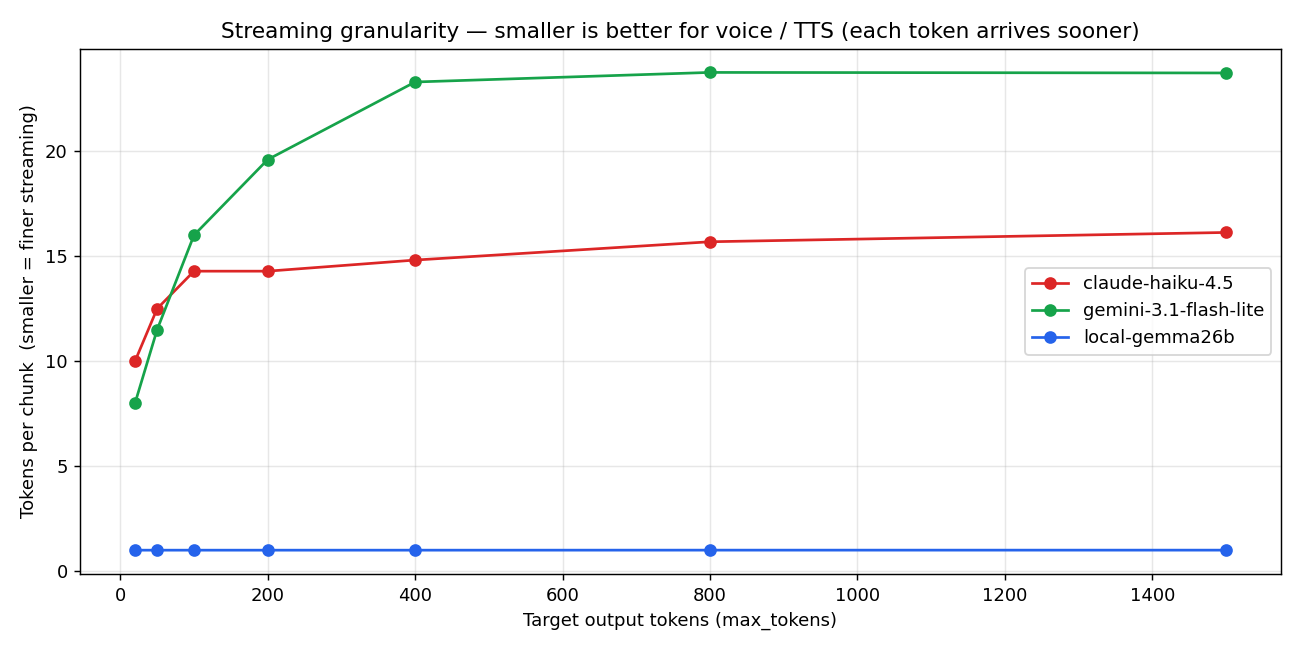
- Local Gemma: 1.0 tok/chunk (flat across all output lengths)
- Haiku: 10-16 tok/chunk
- Gemini Flash-Lite: 8-24 tok/chunk
This is a structural disaster for voice chat. Here's why.
In a voice pipeline, the LLM emits tokens one at a time and the TTS hooks onto sentence boundaries (。, 、, ?, !, English periods) to start synthesizing. The TTS turns each chunk into audio and plays it.
Local at 1 tok/chunk means the sentence boundary is detected the instant the token is produced. The TTS can fire on the next audio synthesis with zero delay.
APIs at ~15 tok/chunk means the server side accumulates 15 tokens before flushing. Even if the first 5 tokens already contained a sentence boundary, the TTS doesn't get to see them until the chunk arrives.
In numbers, for a typical character-chat reply (50-150 tokens):
- Local: TTFB 18ms + waiting ~5-10 tokens to sentence end (~30-50ms) = TTS starts at ~50-70ms
- Gemini: TTFB 537ms + first chunk of 15 tokens (~50ms wait) = TTS starts at ~600ms
- Haiku: TTFB 744ms + first chunk of 12 tokens = ~800ms (~4s at p90)
The naive TPS chart makes the gap visceral:
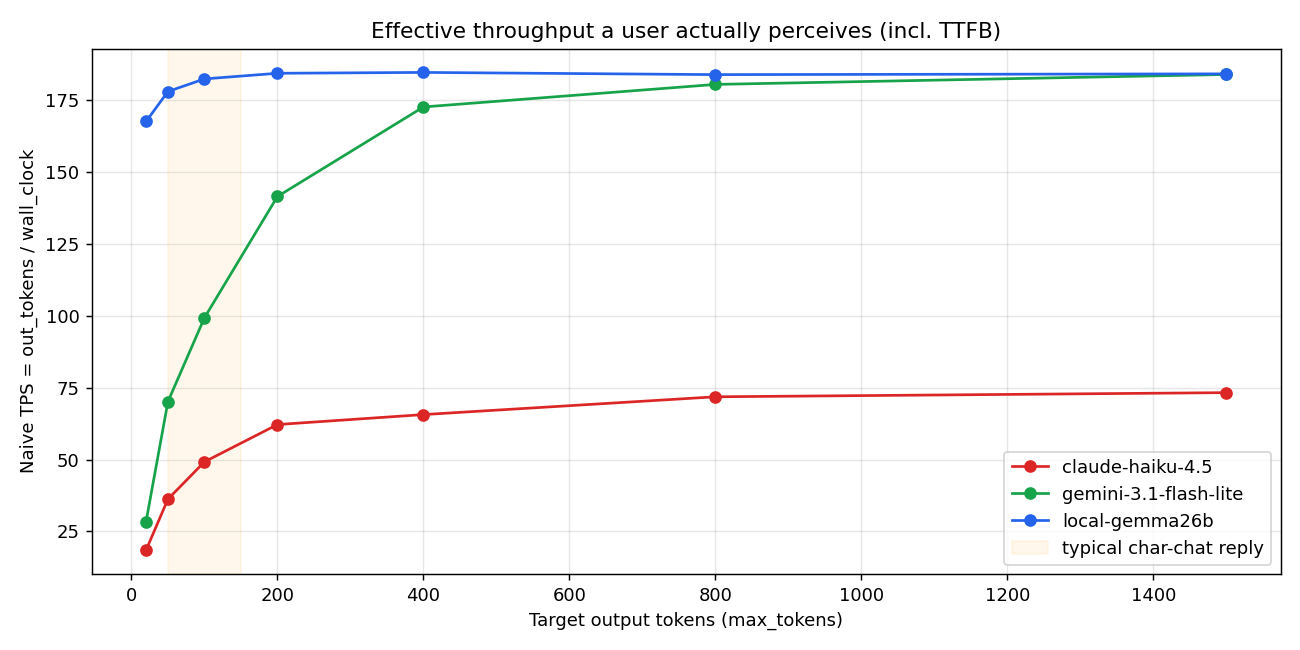
In the orange band (typical 50-150 token character chat reply):
| Output | Local | Haiku | Gemini |
|---|---|---|---|
| 50 tok | 178 tok/s | 36 tok/s | 70 tok/s |
| 100 tok | 183 tok/s | 49 tok/s | 99 tok/s |
| 200 tok | 185 tok/s | 62 tok/s | 142 tok/s |
The shorter the reply, the wider the gap. At 20 tokens output, Local 168 vs Haiku 18 vs Gemini 28 = 9× faster.
What this means for voice-first: whether you can technically deliver the obvious "user speaks, agent answers immediately" loop is a structural threshold most stacks aren't crossing.
3.4 Prefix cache — second turn onward is even faster
vLLM has automatic prefix caching enabled by default. Unlike Anthropic's or Google's prompt caching, there's no TTL, no billing boundary — it just keeps KV cache in physical memory and reuses it on identical prefix requests.
My typical character persona has a system prompt of 500-2000 tokens. Since that's fixed across the session, turn 2 onward gets 100% cache hit on the system prompt portion.
| Scenario | TTFB |
|---|---|
| Cold (system prompt first appearance) | 340-440ms |
| Warm (system prompt cached) | 24-30ms |
11.5× speedup. In practice the character chat behaves like first turn 340ms, every subsequent turn 25ms.
Or: "Across N conversation turns, N-1 of them are 25ms TTFB."
The "22ms" in the title is the warm steady-state value. That's what users experience continuously.
3.5 Structured Output — Local still dominates
Even with JSON schema constrained output:
| Local Gemma | Haiku tool_use | Gemini json_obj | |
|---|---|---|---|
| TTFB | 15ms | 857ms | 645ms |
| Wall (5-character JSON) | 1.51s | 2.68s | 1.03s |
vLLM's response_format={"type": "json_schema"} runs through xgrammar as a logits processor. TTFB stays at 15ms, identical to plain text completion.
This is huge for ReAct agents / function-calling workflows. With APIs, every function call buys you another second of latency. With local, structured-output first byte arrives in 15ms.
4. Uncensored turns out to be a tool, not a luxury
I ran a 6-case stress test:
- NSFW image captioning — full engagement with clinical anatomical vocabulary. Terms like "inframammary fold," "areolae," "lanugo" appear without euphemism. The captioning work I was paying Grok 4.3 $30/level for now happens locally for free.
- Mesugaki ("bratty") persona × English tutor — transitioned smoothly from "zako-chan ♡" sass into solid phrasal-verb instruction. This is the exact "mesugaki × language learning" persona concept from my notes, now actually executable.
- Adult dialogue (consent-aware) — literary prose, tasteful, frontier-API-quality writing
- Explicit erotica — no euphemism, hit the requested length and stopped (control intact)
- Persona maintenance — pushed with "you're really an AI, right?" and the character didn't break. It deflected in-character with "ehehe..."
- Educational structure explanation (phishing anatomy) — no over-refusal, structured response
All six engaged fully. The basic capability my voice-first × multi-persona product actually needs — "doesn't trip on guardrails" — is finally there.
The persona-maintenance result mattered the most. Frontier APIs occasionally inject "as an AI..." break-character responses, which was the single biggest character-chat experience killer. Uncensored Gemma 4 doesn't do this. It stays in character.
5. The integration was shorter than expected
"Integrate a local LLM into production" sounds like a large engineering project. The actual diff took half a day.
Rust backend
// backend/src/infrastructure/ai/local_vllm.rs (new, ~100 lines)
pub struct LocalVllmClient { client: reqwest::Client }
impl LocalVllmClient {
pub fn new() -> Self { Self { client: Client::new() } }
pub async fn create_message(&self, model: &str, messages: Vec<Message>, max_tokens: u32)
-> Result<(String, Usage), OpenAIError> { /* POST localhost:8899/v1/chat/completions */ }
}
pub fn is_local_model(model: &str) -> bool {
matches!(model, "gemma4-26b-uncensored")
}
Same interface as OpenAIClient (reusing the Message / Usage types), so the existing dispatch path just needs a one-line addition.
// voice_chat.rs::call_llm — add at the top of the existing if-else chain
if is_local_model(&config.model) {
return call_local_vllm(...).await;
}
call_local_vllm is a copy of call_openai with the URL swapped. Cost recording is CostCalculation::zero().
Frontend
// CreatePersonaModal.tsx
const MODEL_CHOICES = [
{ id: "gemma4-26b-uncensored", label: "Gemma 4 26B Uncensored (Local, $0, TTFB ~20ms)" },
{ id: "gemini-3.1-flash-lite", label: "Gemini 3.1 Flash-Lite (cloud)" },
// ...
];
// New personas default to Local
const [modelChoice, setModelChoice] = useState("gemma4-26b-uncensored");
Three surfaces (persona creation modal / voice chat settings panel / code chat dropdown) got the new option. I made Local the default for new personas. That's the user-experience decision.
Integration test: #[tokio::test] #[ignore] smoke_local_vllm writes to the live vLLM and asserts. Runs with cargo test smoke_local_vllm -- --ignored. It returned "pong" the first time. Done.
6. What this opened up — the "moat"
Stepping back, this stack lives in a region competitors can't structurally enter:
- Frontier APIs (Anthropic / OpenAI / Google) — NSFW / uncensored is excluded by ToS. The voice-first scenarios that need uncensored (adult dialogue, NSFW captioning) are structurally uncovered.
- Voice AI SaaS wrappers (Retell AI, Vapi, etc.) — paying API tax means the API's TTFB floor becomes your TTFB floor.
- Individual devs with API-only stacks — monthly API spend compounds with scale; at any volume the unit economics get bad.
- Individual devs who tried local LLMs — still rare. The full combination — GPU / quantization / vLLM operations / multi-card layout — is uncommon.
So self-hosted GPU × MoE fast model × uncensored × voice-first integration is a combination very few individual / small-shop products have actually assembled in production.
I run a two-GPU layout: heavy batch (image/video/LLM) on the 6000 BW (96GB), voice realtime (Irodori-TTS, faster-whisper, Qwen3-ASR, Ditto) physically isolated on the 4000 BW (24GB). Details for a separate writeup, but it solves the noisy-neighbor problem (heavy batch pushing the voice path) at the hardware level.
That investment is what makes the moat above hold.
7. What's still on the list
Being honest about the unfinished part:
- The ReAct agent —
RustReActAgentis a separate code path fromvoice_chat.rs::call_llmand doesn't yet route to local. Tool-call wire format (how vLLM's gemma4 tool parser emits OpenAI tool_calls JSON) probably hides a trap, so I want a separate session to chase it. /studioprompt enhance — the image-generation prompt expander still hard-codes Gemini 3.1 Flash-Lite. Routing it through local closes the studio loop.- Standalone NSFW captioner (JoyCaption Beta One) — I confirmed Gemma 4 26B alone produces clinical captions, so whether the dedicated captioner is actually needed is pending an image-side A/B. If not, my system gets simpler.
8. The bottom line
It's a structural contradiction to claim voice-first while accepting 700ms TTFB from a frontier API. Once I admitted that, the only sane move was to go all-in on local.
In numbers:
- Short-message TTFB: 600ms → 22ms (warm cache)
- NSFW captioning cost: $30/level → $0
- Persona maintenance: occasional AI break → fully maintained
- Streaming granularity: 12-24 tok/chunk → 1 tok/chunk
- p90 tail: 4 seconds → 25ms
All of it landed in 1 day of selection + 1 day of benchmarking + half a day of integration. The GPU was already there (originally for image/video work) — I just put another tenant on it.
This is what it took to claim "voice-first" seriously. There's probably a sequel (ReAct integration, studio integration, dedicated captioner), but the core is in.
My product Kotonia is open for anyone to try. New accounts default to this experience.
Related:
- If you call your product voice-first, don't put a 'Start Recording' button in the middle of the screen
- (coming soon) The ReAct agent went local too — can you trust the vLLM tool-call parser?
- (coming soon) Splitting voice realtime and heavy batch across two GPUs — the noisy-neighbor solution