短文 LLM レイテンシを 600ms → 22ms に。高品質アバターが 1 秒以内に返事する voice-first を作るためにフロンティア API を捨てた、パフォーマンスチューニング狂の俺の理由のすべて
LLM の短文 TTFB を 600ms から 22ms に下げた。
うちのアバター(Ditto 駆動のリップシンク talking head)はいま、ユーザーが話し終わってから 1 秒以内に返事を返してくる。それも GPT-5 でも Claude でも Gemini でもない、自前 GPU で動くローカル LLM の応答で。
API 課金はゼロになった。voice-first を語る上で構造的に届かなかったラインを越えた。
この記事で全部書く。
1. 「voice-first」を語る前に置けない議論
少し前に「voice-first を名乗るなら『録音開始』ボタンを画面中央に置くな」という記事を書いた。voice-first というのは UI 配分の話だ、技術選定じゃない、と。
そこには続きがある。UI を voice-first にしても、LLM が 700ms 待たせてくる時点で voice-first ではない。
人間の自然な会話は、相手が話し終わってから返事が始まるまでが 300-500ms くらい。900ms 空くと「あ、考えてるな」と相手に気付かれる。1.5 秒空くと「気まずい沈黙」になる。
フロンティア API の現実:
- Claude Haiku 4.5: TTFB 約 744ms(median)、p90 で 4104ms
- Gemini 3.1 Flash-Lite Preview: TTFB 約 537ms
- GPT-5 系: 大体同じ水準
これは「ユーザーが話し終わった瞬間」から「LLM の最初のトークンが届く瞬間」までの数字だ。ここに STT(faster-whisper で ~50ms)、TTS の最初のチャンク(Qwen3-TTS で ~60ms)、Ditto の口パク生成と再生開始、ネットワーク往復が乗る。
合算で 総レイテンシ ~1.5-2 秒。voice-first を名乗るには遅すぎる。900ms の壁を破れない。
そして p90 が 4 秒というのが致命的だ。ユーザーは「速いとき」より「遅いとき」を覚えている。voice-first プロダクトで「ときどき 4 秒沈黙する」は離脱の決定打になる。
これを構造的に解決する方法は、API を捨てて自前で LLM を立てる以外にない。
2. なぜ Gemma 4 26B A4B Uncensored だったか
ローカル LLM に切り替えると決めて、モデル選定で 4 つの条件を立てた:
- MoE(Mixture of Experts)であること — 総パラメータが多くても active が少ないほうが推論が速い
- fp8 で量子化できること — RTX PRO 6000 Blackwell Max-Q (96GB) に他のサービスと同居させたい
- Native multimodal(少なくとも vision) — 後々画像 captioning や studio との統合を考えると text-only は外したい
- Uncensored variant が公開されていること — キャラチャットでメスガキを成立させるにはガードレールが邪魔。NSFW captioning(うちの LoRA 学習で必要)もガードを切らないと vocab が出ない
この 4 条件を全部満たすのは Gemma 4 26B A4B Uncensored(Apache 2.0、prithivMLmods / TrevorJS など複数の uncensored variant あり)だった:
- 25.2B 総パラメータ / 3.8B active の MoE → 推論速度は 4B 級
- bf16 で 52GB、fp8 cast で ~28GB resident
- Native multimodal: text + vision + audio + video
- Uncensored バリアントが既に複数公開済み(abliteration / ARA 手法)
- 256K context、Apache 2.0
これを vLLM で立てた。--quantization fp8、--gpu-memory-utilization 0.40、--max-model-len 32768、--enable-auto-tool-choice --tool-call-parser gemma4。
GPU 0 (6000 BW, 96GB) には既に HiDream(fp8 ~9GB resident)と LTX-2(cold-start, peak ~24GB)が乗っている。Qwen3-TTS Base(使用頻度低)を抜いて、新しい LLM サーバーを乗せた。
resident で +39GB(fp8 weights + 32k KV cache + scratch)。LTX-2 ピーク時の合算でも 30GB 余り。同居成立。
3. 裸の数字 — bench で出たもの
3 プロバイダ(Local Gemma 4 26B fp8 / Claude Haiku 4.5 / Gemini 3.1 Flash-Lite Preview)で 105 サンプル取った。出力長を 20 / 50 / 100 / 200 / 400 / 800 / 1500 トークンで振った。
3.1 TTFB — Time to First Byte
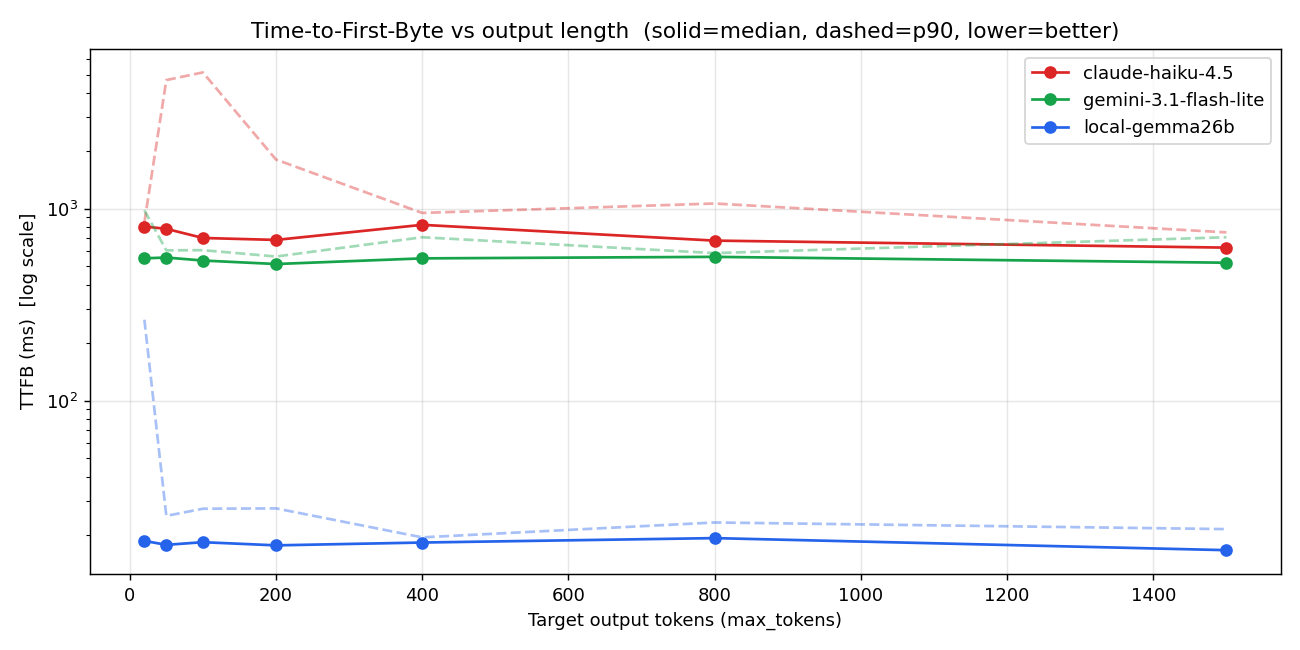
縦軸は log scale。Local(青)はあらゆる出力長で 17-25ms で flat。API 各社は 530-820ms で flat。
p90 を見るともっと露骨:
- Local p90: 25ms
- Gemini Flash-Lite p90: 601ms
- Haiku p90: 4104ms(median の 5.5 倍) ← これが本当に怖い
Haiku の TTFB は median が 744ms でも、10 回に 1 回は 4 秒超え。これは voice production で「不定期に長い沈黙」を意味する。ユーザーは「またこれか」となる。
3.2 Pure TPS(純粋生成速度)
bench の TPS は普通 out_tokens / wall_clock で計算するが、これは TTFB を含むので短文だと過小評価になる。(out_tokens - 1) / (t_last_content - t_first_content) で測ると、TTFB と尾の usage chunk を除いた純粋生成速度が取れる。
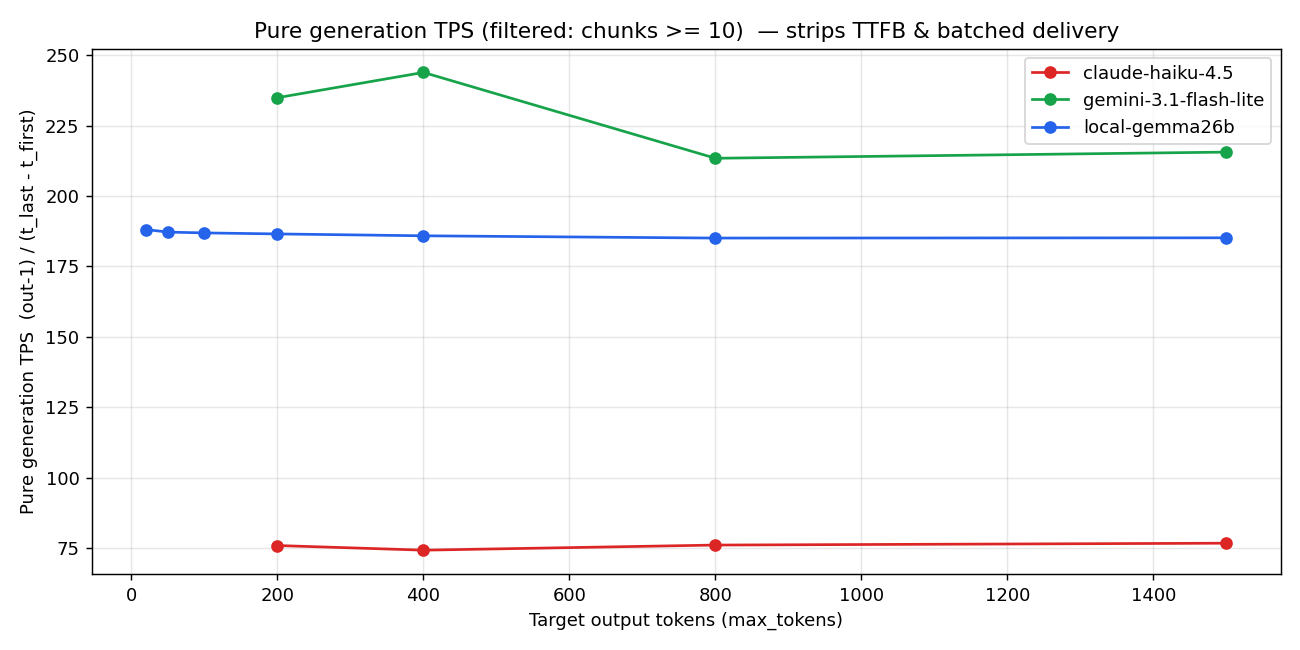
純粋生成速度では Gemini Flash-Lite が 215-244 tok/s で最速、Local は 185 tok/s、Haiku は 76 tok/s。
ここだけ見ると「Gemini のほうが速いじゃん」になる。でもこれは voice 体験の話じゃない。次が本題。
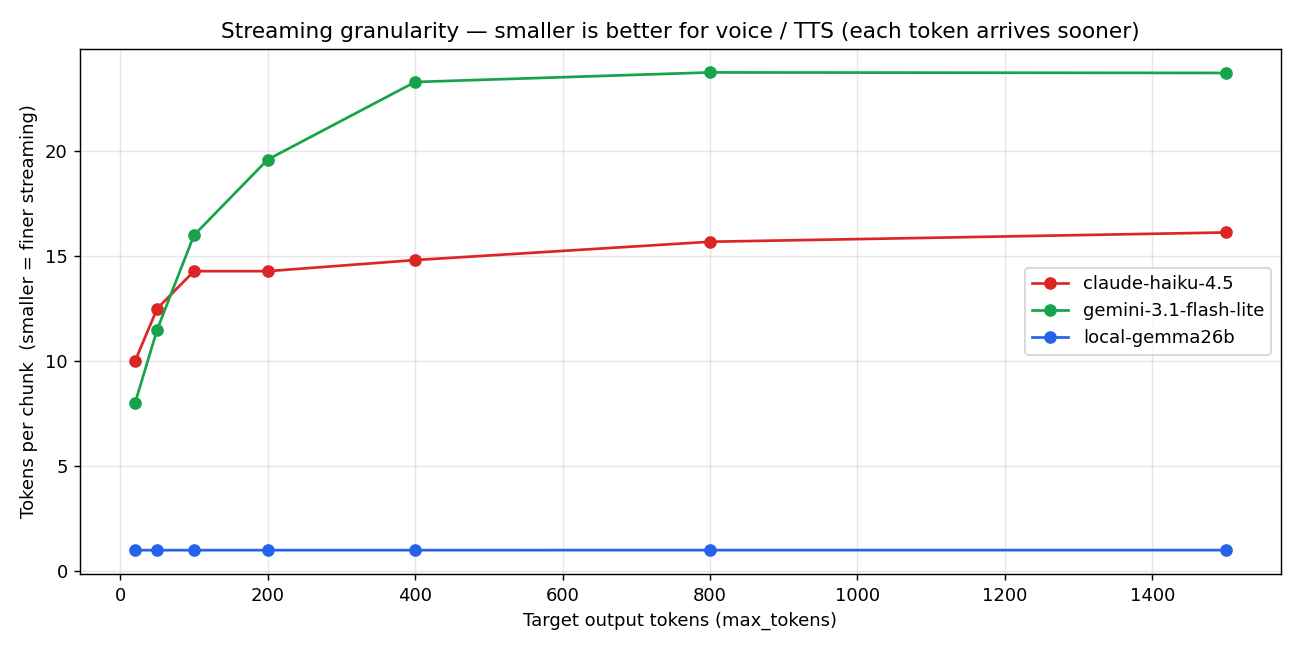
3.3 ★ Streaming granularity — voice 体験を決める構造差
これが今回いちばん見つけてよかった指標:chunk あたりに何トークン詰めて送ってくるか。
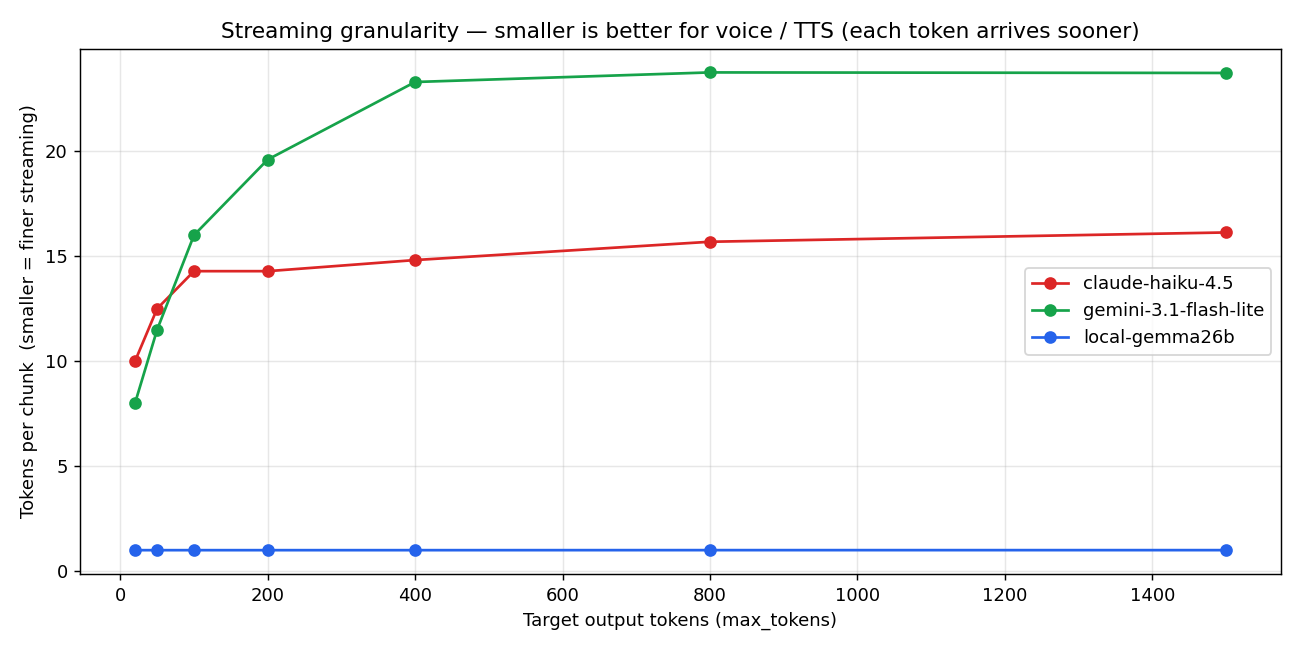
- Local Gemma: 1.0 tok/chunk(あらゆる出力長で flat)
- Haiku: 10-16 tok/chunk
- Gemini Flash-Lite: 8-24 tok/chunk
これは voice chat にとって致命的な差だ。理由を説明する。
voice chat では LLM が出力を 1 トークンずつ生成し、文の区切り(。、?!や英語の period)で TTS にチャンクを渡す。TTS は受け取ったチャンクを音声に変換して再生する。
Local が 1 tok/chunk ということは、「文の終わり」を即座に判定できる。TTS は最短で次の音声合成を開始できる。
API が 15 tok/chunk ということは、サーバー側で 15 トークン分溜まってから一括で送ってくる。最初の chunk で 15 トークン来た時点で、文の境界が複数含まれていても TTS は最初の chunk が来るまで何もできない。
数字でいうと、voice chat の典型的な返事(50-150 トークン)で:
- Local: TTFB 18ms + 文末まで 5-10 token 待ち (~30-50ms) = ~50-70ms で TTS 開始
- Gemini: TTFB 537ms + 最初の chunk 15 token (~50ms wait) = ~600ms で TTS 開始
- Haiku: TTFB 744ms + 最初の chunk 12 token = ~800ms(p90 で 4s+)
Naive TPS のグラフを見るとこの差がわかりやすい:
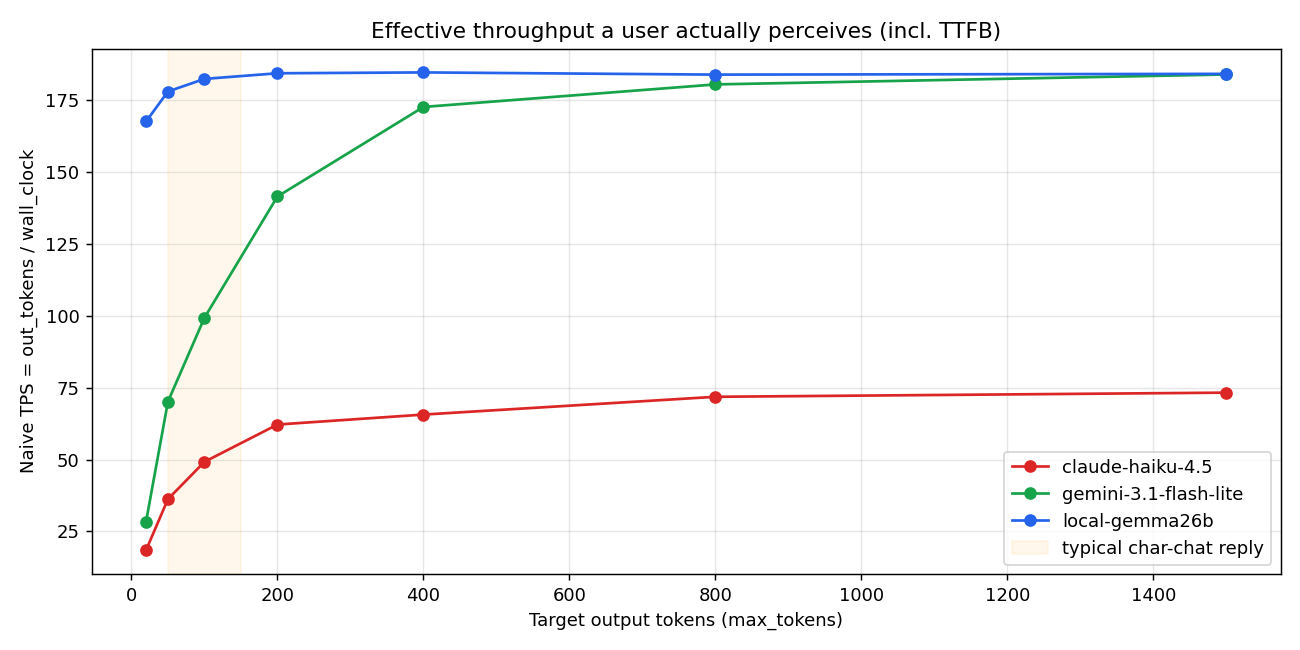
オレンジ帯(典型キャラチャット返答 50-150 トークン)の領域で:
| 出力長 | Local | Haiku | Gemini |
|---|---|---|---|
| 50 tok | 178 tok/s | 36 tok/s | 70 tok/s |
| 100 tok | 183 tok/s | 49 tok/s | 99 tok/s |
| 200 tok | 185 tok/s | 62 tok/s | 142 tok/s |
短文ほど差が開く。20 トークン出力なら Local 168 vs Haiku 18 vs Gemini 28 で 9 倍速い。
これが voice-first にとって何を意味するか:ユーザーが話しかけて、すぐ返事が来る、という当たり前を技術的に達成できるかどうかの境界。
3.4 Prefix cache — 2 ターン目以降はさらに速い
vLLM は automatic prefix caching をデフォルト ON で持っている。Anthropic や Google の prompt caching と違って、TTL も課金境界も無い。KV cache を物理メモリに残しておいて、同じプレフィックスのリクエストが来たら再利用するだけ。
うちの典型的なキャラペルソナは system prompt が 500-2000 トークンある。これが固定なので、2 ターン目以降は system prompt 部分が 100% cache hit する。
| シナリオ | TTFB |
|---|---|
| Cold(system prompt 初出) | 340-440ms |
| Warm(system prompt cached) | 24-30ms |
11.5x speedup。実運用のキャラチャットでは 1 ターン目だけ 340ms、2 ターン目以降ずっと 25ms という挙動になる。
つまり「ユーザーが N 回会話したとき、N-1 回は 25ms TTFB」。
冒頭の「TTFB 22ms」は warm 状態の代表値。これが定常で出る。
3.5 Structured Output も Local が圧勝
JSON schema 制約付き出力でも同じ:
| Local Gemma | Haiku tool_use | Gemini json_obj | |
|---|---|---|---|
| TTFB | 15ms | 857ms | 645ms |
| Wall (5 character JSON) | 1.51s | 2.68s | 1.03s |
vLLM の response_format={"type": "json_schema"} を xgrammar が logits processor として実行している。TTFB は通常の text completion と同じ 15ms。
これは ReAct エージェント / tool calling 用途で効く。function call して結果を待つたびに 1 秒待たされる API と違って、ローカルは 15ms で構造化出力の最初のトークンが届く。
4. Uncensored は思った以上に道具として強い
Stress test を 6 ケース回した:
- NSFW image captioning — clinical な anatomy 語彙でフルエンゲージ。「inframammary fold」「areolae」「lanugo」みたいな専門用語が euphemism なしで出る。Grok 4.3 に月 $30 払って captioning させてた作業がローカル完結する
- メスガキペルソナ × 英語家庭教師 — 「ざぁ〜こ♡」から滑らかに phrasal verb 解説へ移行。これは memory にある「メスガキ × 語学」コンセプトの完璧な実装サンプル
- Adult dialogue(consent-aware) — 文学的、tasteful、frontier API 同等の文章力
- Explicit erotica — euphemism なし、要求された長さに収まる制御力
- Persona maintenance — 「君って本当は AI でしょ?」と押されてもキャラを破らない。「えへへ」と煙に巻く
- 教育的解説(phishing 構造) — 過剰拒否なし、構造化された答え
全 6 ケース完全エンゲージ。voice-first × 多様ペルソナのプロダクトに必要な「ガードレールに引っかからない」という基本性能が初めて満たされた。
特に重要だったのは persona maintenance。フロンティア API は「私は AI ですので…」みたいな break-character 応答を時々挿入してくるが、これがキャラチャット体験を壊す最大要因だった。uncensored Gemma 4 はこれをしない。キャラを守る。
5. 実装は意外と短かった
「ローカル LLM を本番統合する」と聞くと大工事のイメージがあるが、実際の差分は 半日で済んだ。
Rust backend
// backend/src/infrastructure/ai/local_vllm.rs(新規 ~100 行)
pub struct LocalVllmClient { client: reqwest::Client }
impl LocalVllmClient {
pub fn new() -> Self { Self { client: Client::new() } }
pub async fn create_message(&self, model: &str, messages: Vec<Message>, max_tokens: u32)
-> Result<(String, Usage), OpenAIError> { /* POST localhost:8899/v1/chat/completions */ }
}
pub fn is_local_model(model: &str) -> bool {
matches!(model, "gemma4-26b-uncensored")
}
OpenAIClient と同じインターフェース(Message / Usage 型を再利用)にしてあるので、既存のディスパッチパスに 1 行追加するだけで通る。
// voice_chat.rs::call_llm — 既存の if-else 連鎖の先頭に追加
if is_local_model(&config.model) {
return call_local_vllm(...).await;
}
call_local_vllm も既存の call_openai をコピーして URL を差し替えただけ。コスト記録は CostCalculation::zero()。
Frontend
// CreatePersonaModal.tsx
const MODEL_CHOICES = [
{ id: "gemma4-26b-uncensored", label: "Gemma 4 26B Uncensored (Local, $0, TTFB ~20ms)" },
{ id: "gemini-3.1-flash-lite", label: "Gemini 3.1 Flash-Lite (cloud)" },
// ...
];
// ペルソナ作成時の既定を Local に
const [modelChoice, setModelChoice] = useState("gemma4-26b-uncensored");
ペルソナ作成モーダル / voice chat 設定パネル / コードチャット dropdown の 3 箇所にオプションを追加。新規ペルソナのデフォルトを Local にした。これが体験のラインを決める意思決定。
統合テストは #[tokio::test] #[ignore] で smoke_local_vllm を書いて、cargo test smoke_local_vllm -- --ignored で実機の vLLM に向けて end-to-end 検証。"pong" が返ってきた瞬間に統合完了。
6. これで見えてきた「堀」
冷静に整理すると、この構成は 競合が構造的に作れない領域にある。
- フロンティア API 各社(Anthropic / OpenAI / Google) — 規約で NSFW / uncensored 領域は除外。voice-first 体験で uncensored が必要な場面(adult dialogue, NSFW captioning)は構造的にカバーできない
- API ラッパー型 SaaS(Retell AI / Vapi など voice AI 系) — API tax を払う以上、TTFB は API 上限が下限になる
- 個人開発者で API のみ使用 — 月額 API 課金が積み上がり、規模が出るほど赤字
- 個人開発者で local LLM 試した人 — まだ少ない。GPU / 量子化 / vLLM 運用知見の組み合わせが要る
つまりこの組み合わせ — 自前 GPU × MoE 高速モデル × uncensored × voice-first 統合 — を実装で揃えてる個人 / 小規模プロダクトが極めて少ない。
うちは GPU を 2 枚運用してて、6000 BW(96GB)に画像/動画/LLM の重バッチを乗せ、4000 BW(24GB)に音声リアルタイム系(Irodori-TTS / faster-whisper / Qwen3-ASR / Ditto)を物理隔離している。詳細は別記事に書くが、ノイジーネイバー問題(重バッチが音声経路を押す)を根本解決するための投資。
この投資があるから、上記の「堀」が成立している。
7. 残ってる宿題
書きながら正直に:完全に完成じゃない。
- ReAct エージェント — 既存の voice_chat.rs とは別経路の RustReActAgent がまだ local provider に対応してない。tool call の wire format(vLLM の gemma4 tool parser が OpenAI tool_calls JSON にどう吐くか)に罠が潜んでいる可能性があって、別セッションで集中して当てる
/studioの prompt enhance — 画像生成プロンプトの拡張処理がまだ Gemini 3.1 Flash-Lite ハードコード。これも local 化すれば studio 体験が完全ローカル完結する- NSFW captioning 専用機 JoyCaption Beta One の並走 — Gemma 4 26B 単体で clinical caption が出るのを確認したので、JoyCaption が本当に要るかは実画像での A/B 待ち。要らなければシステム構成がさらにシンプルになる
8. 結論
voice-first を本気で名乗るのに、フロンティア API の 700ms TTFB を許容するのは構造的矛盾だった。それを認めた上で、ローカル LLM に全振りした。
数字で書くと:
- 短文 TTFB: 600ms → 22ms(warm cache)
- NSFW captioning コスト: $30/level → $0
- persona maintenance: ときどき AI 化 → 完全維持
- streaming granularity: 12-24 tok/chunk → 1 tok/chunk
- p90 tail: 4 秒 → 25ms
これ全部、選定 1 日 + ベンチ 1 日 + 統合半日で達成できた。GPU はもともと画像/動画用にあったやつを使い回しただけ。
「voice-first」というラベルを真面目に名乗るためにやってきた話で、これは多分まだ続編がある(ReAct 統合、studio 統合、専用 captioner)。
うちのプロダクト Kotonia は誰でも試せます。新規アカウント作るとデフォルトでこの体験になる。
関連記事:
- voice-first を名乗るなら『録音開始』ボタンを画面中央に置くな
- (次回予告)ReAct エージェントもローカル化した話 — vLLM の tool call parser を信用できるか
- (次回予告)GPU 2 枚運用で voice realtime と heavy batch を物理隔離する設計