短消息 LLM 延迟从 600ms 降到 22ms。让高质量虚拟形象在 1 秒内开口回应——一个性能调优狂为什么放弃前沿 API 全押本地 LLM 的完整告白
我把 LLM 短消息的 TTFB 从 600ms 砍到了 22ms。
我的虚拟形象(Ditto 驱动的对口型 talking head)现在能在用户说完话后的 1 秒内开口回应。背后跑的不是 GPT-5、不是 Claude、也不是 Gemini,而是部署在自己 GPU 上的本地 LLM。API 月费归零。"voice-first" 这块招牌从结构上原本够不到的那条线,终于跨过去了。
这篇文章把整个过程全部讲清楚。
1. 在声称"voice-first"之前必须先承认的一件事
之前我写过一篇文章主张:你的产品如果号称 voice-first,就不能在屏幕中央放一个"开始录音"按钮。voice-first 是 UI 的比例问题,不是技术栈问题。
那个论点有续集。即使 UI 是 voice-first,只要 LLM 让用户等 700ms,你的产品就不是 voice-first。
人类自然对话中,"对方话音落下"到"对方开口"的间隔大约是 300-500ms。900ms 时对方会觉察"在思考",到 1.5s 就变成"尴尬的沉默"。
前沿 API 的现实:
- Claude Haiku 4.5:TTFB 中位数 约 744ms,p90 高达 4104ms
- Gemini 3.1 Flash-Lite Preview:TTFB 约 537ms
- GPT-5 系列:同一档次
这只是 LLM 那一段。之上还要叠加 STT(faster-whisper ~50ms)、TTS 首块(Qwen3-TTS ~60ms)、Ditto 虚拟形象的启动、网络往返。
合计感知延迟落在 1.5-2 秒。慢到没法称为 voice-first。打不破 900ms 那堵墙。
最致命的是 p90。用户记住"慢的那次",远比记住"快的几次"深。"偶尔静默 4 秒" 是 voice 类产品最大的流失驱动因素。
要从结构上解决这一点,唯一的办法就是放弃 API,自建 LLM。
2. 为什么偏偏选 Gemma 4 26B A4B Uncensored
决定切到本地后,我立了四条选型条件:
- MoE(专家混合) — 总参数可以大,但只要活跃参数低,推理就快
- 能 fp8 量化 — 要和 RTX PRO 6000 Blackwell Max-Q (96GB) 上的其他服务共存
- 原生多模态(至少 vision) — 后续涉及图像 captioning 和 studio 集成,纯文本模型直接出局
- 必须有公开的 uncensored 版本 — 角色聊天里的"傲娇小恶魔英语家教"会被前沿安全过滤器误伤;NSFW captioning(我的 LoRA 训练管线需要)需要解掉护栏才能正确输出术语
四条同时满足的,只有一个:Gemma 4 26B A4B Uncensored(Apache 2.0,prithivMLmods / TrevorJS 等多个 uncensored 变体已发布):
- 总参数 25.2B,活跃参数 3.8B 的 MoE → 推理速度接近 4B dense
- bf16 下 52GB,fp8 cast 后 ~28GB 常驻
- 原生多模态:text + vision + audio + video
- Uncensored 变体已发布(abliteration / ARA 等手法)
- 256K context、Apache 2.0
我用 vLLM 起的:--quantization fp8、--gpu-memory-utilization 0.40、--max-model-len 32768、--enable-auto-tool-choice --tool-call-parser gemma4。
GPU 0(6000 BW,96GB)原本已经有 HiDream(fp8 ~9GB 常驻)和 LTX-2(cold-start,峰值 ~24GB)。我把使用率低的 Qwen3-TTS Base 撤掉,把新 LLM 服务塞进那个槽位。
常驻 +39GB(fp8 权重 + 32k KV cache + scratch)。即使 LTX-2 峰值同时发生,也还剩 30GB 余量。共存成立。
3. 裸数据 — bench 实际跑出来的东西
我对三家 provider(本地 Gemma 4 26B fp8 / Claude Haiku 4.5 / Gemini 3.1 Flash-Lite Preview)取了 105 个样本,输出长度在 20 / 50 / 100 / 200 / 400 / 800 / 1500 tokens 上变化。
3.1 TTFB — Time to First Byte
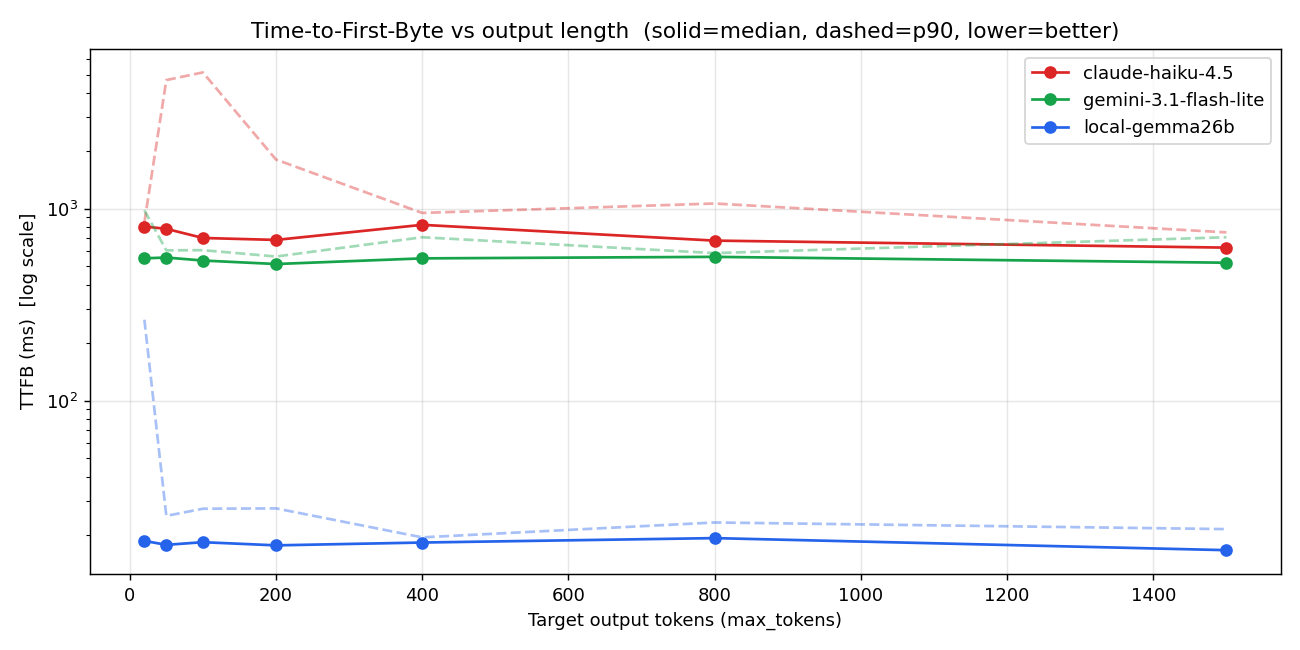
Y 轴是 log scale。Local(蓝)在所有输出长度上都是 17-25ms,纹丝不动。API 各家在 530-820ms 之间,也是 flat。
p90 数据更狠:
- Local p90:25ms
- Gemini Flash-Lite p90:601ms
- Haiku p90:4104ms(是中位数的 5.5 倍) ← 这个真的可怕
Haiku 中位数虽然 744ms,但每 10 次调用就有 1 次超过 4 秒。这在 voice 生产环境里就是"不定时出现的 4 秒静默"。用户会发现,然后离开。
3.2 Pure TPS(纯生成速度)
通用的 TPS 计算是 out_tokens / wall_clock,但这包含了 TTFB 和尾部,对短输出来说会低估生成速度。如果改用 (out_tokens - 1) / (t_last_content - t_first_content),剥离 TTFB 和尾部 usage chunk,就能拿到纯生成速度。
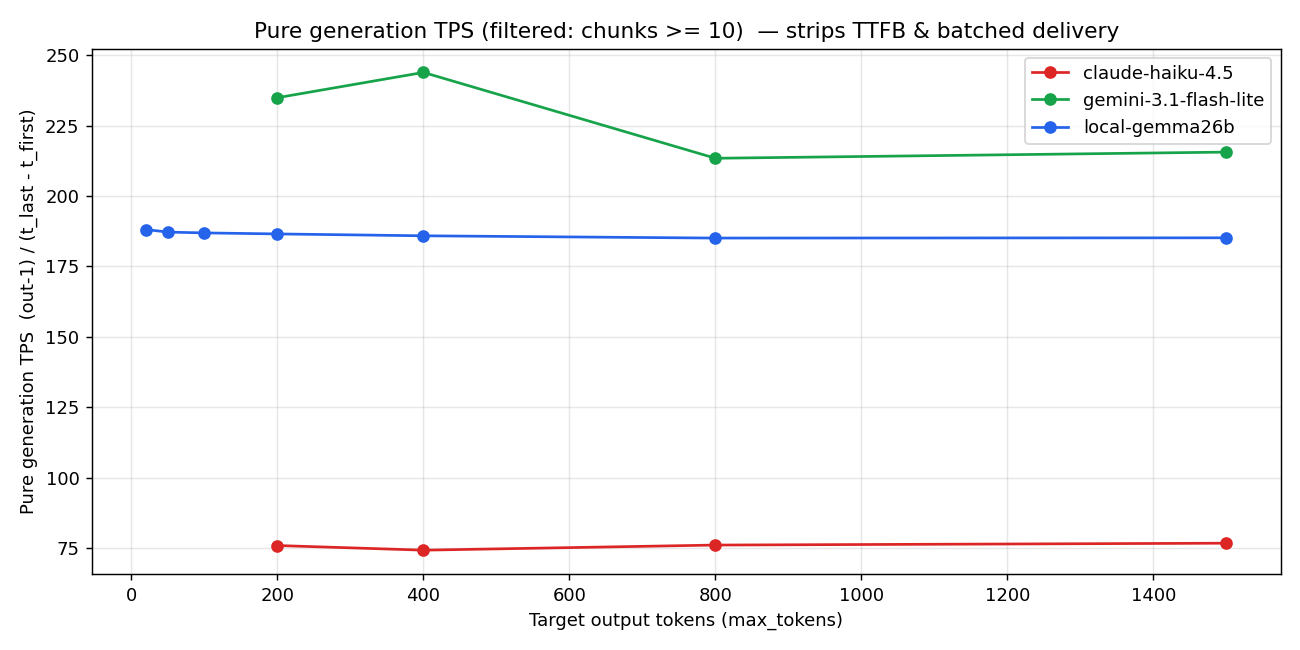
纯生成速度榜单:Gemini Flash-Lite 215-244 tok/s 第一,Local 185 tok/s,Haiku 76 tok/s。
只看这张图你可能会想"Gemini 更快啊"。但 voice-chat 看的不是这个。下一节才是重点。
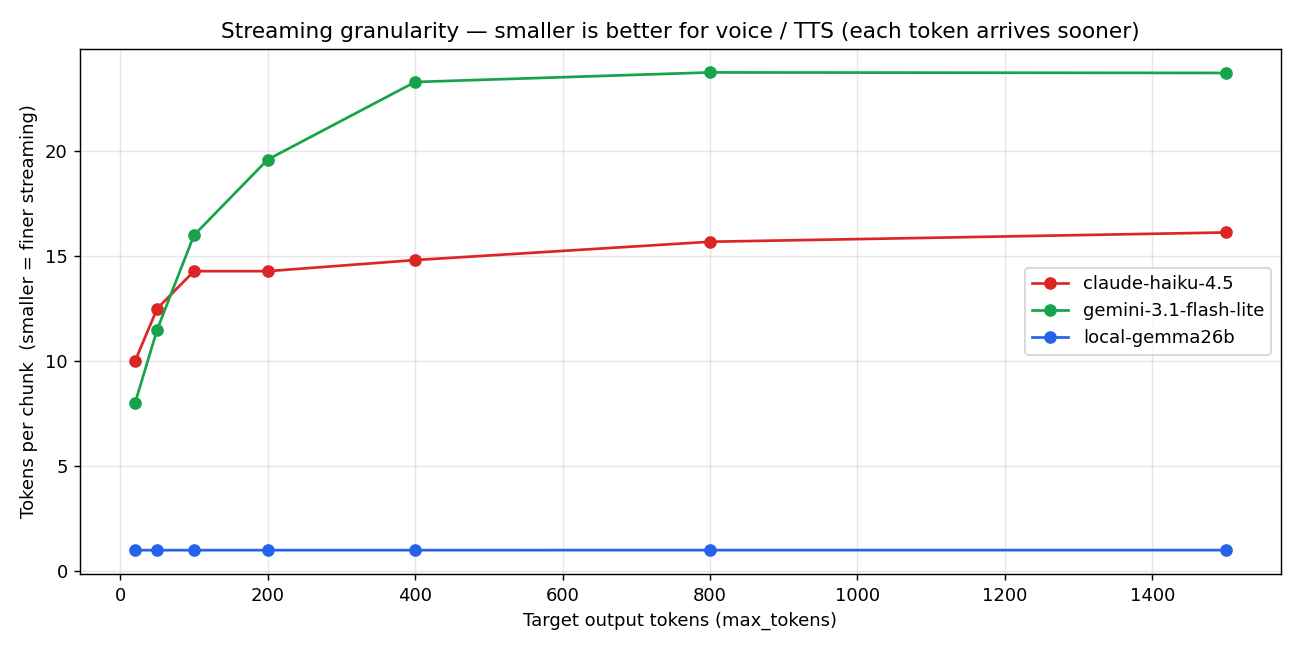
3.3 ★ 流式粒度 — 决定 voice 体验的结构差
这是这一轮发现最值的指标:每个 streaming chunk 里塞了多少个 token。
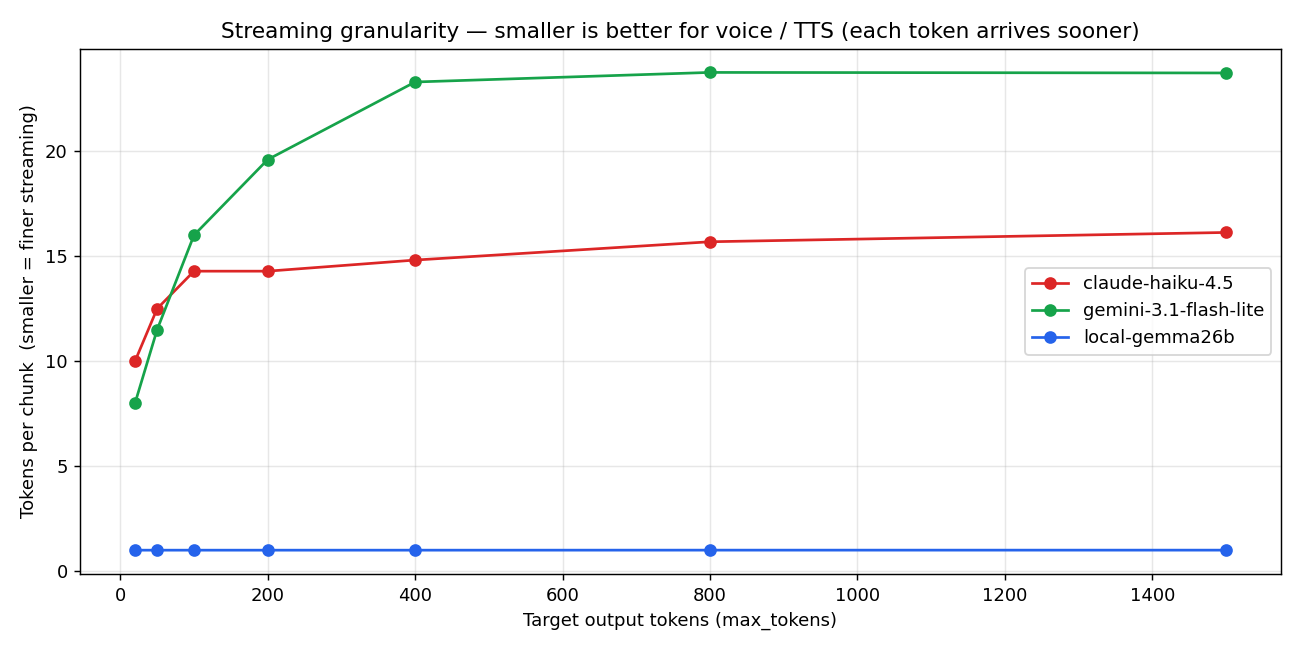
- Local Gemma:1.0 tok/chunk(所有输出长度上都是 flat)
- Haiku:10-16 tok/chunk
- Gemini Flash-Lite:8-24 tok/chunk
这对 voice chat 是结构性灾难。原理如下。
voice 管线里,LLM 一个 token 一个 token 地输出,TTS 在句子边界(。、、、?、! 或英文 period)触发音频合成。TTS 把 chunk 转成音频并播放。
Local 是 1 tok/chunk,意味着 token 一生成出来,句子边界就立刻能检测到。TTS 可以在最短时间内启动下一段合成。
API 是 ~15 tok/chunk,意味着服务端要攒到 15 tokens 才一并发送。即使前 5 个 token 已经包含了句子边界,TTS 也得等到这个 chunk 抵达才看得到。
换算成实际数字(典型角色聊天回复 50-150 tokens):
- Local:TTFB 18ms + 等到句末 ~5-10 token (~30-50ms) = ~50-70ms 启动 TTS
- Gemini:TTFB 537ms + 首 chunk 15 token (~50ms 等待) = ~600ms 启动 TTS
- Haiku:TTFB 744ms + 首 chunk 12 token = ~800ms(p90 时 4 秒+)
Naive TPS 图把差距显示得很直观:
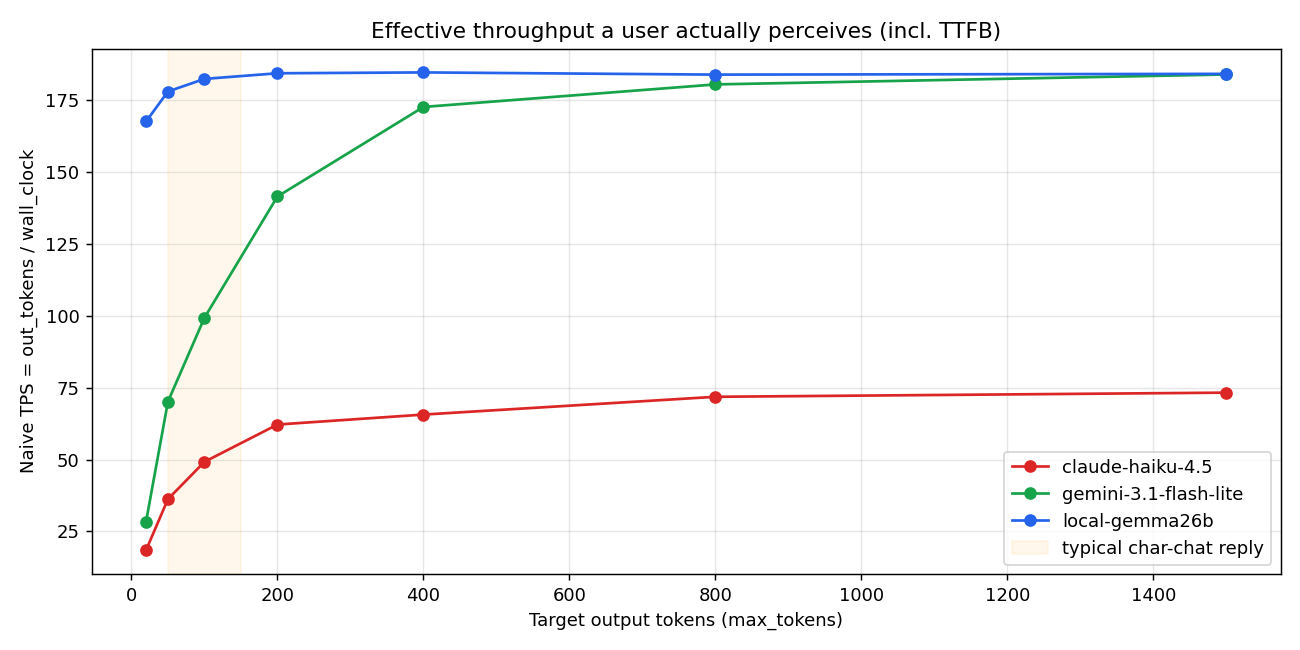
橙色带(典型角色聊天回复 50-150 tokens)区间内:
| 输出长度 | Local | Haiku | Gemini |
|---|---|---|---|
| 50 tok | 178 tok/s | 36 tok/s | 70 tok/s |
| 100 tok | 183 tok/s | 49 tok/s | 99 tok/s |
| 200 tok | 185 tok/s | 62 tok/s | 142 tok/s |
回复越短差距越大。20 token 输出时,Local 168 vs Haiku 18 vs Gemini 28 = 9 倍速度。
这对 voice-first 意味着什么:"用户开口,AI 立刻回应"这种天经地义的循环能不能技术上达成,本身就是绝大多数技术栈跨不过的结构门槛。
3.4 Prefix cache — 第 2 轮起更快
vLLM 默认开启 automatic prefix caching。和 Anthropic、Google 的 prompt caching 不同,这里没有 TTL、没有计费边界——单纯把 KV cache 留在物理内存里,遇到相同前缀的请求就复用。
我典型的角色 persona 有 500-2000 tokens 的 system prompt。这部分在整个会话中是固定的,所以第 2 轮起 system prompt 部分会 100% 命中 cache。
| 场景 | TTFB |
|---|---|
| Cold(system prompt 首次) | 340-440ms |
| Warm(system prompt 已缓存) | 24-30ms |
加速 11.5x。实际运行中角色聊天的行为是 "第一轮 340ms,之后每轮 25ms"。
换句话说:"N 轮对话中,N-1 轮都是 25ms TTFB"。
标题里的"22ms"是 warm 稳态的代表值。这才是用户实际持续体验到的数字。
3.5 结构化输出(Structured Output)也是 Local 赢
带 JSON schema 约束的输出也一样:
| Local Gemma | Haiku tool_use | Gemini json_obj | |
|---|---|---|---|
| TTFB | 15ms | 857ms | 645ms |
| Wall(5 角色 JSON) | 1.51s | 2.68s | 1.03s |
vLLM 的 response_format={"type": "json_schema"} 是 xgrammar 作为 logits processor 实现的。TTFB 跟普通 text completion 一样还是 15ms。
这对 ReAct agent / function calling 工作流很重要。用 API 时,每次 function call 都要等近 1 秒;本地这边 15ms 就能拿到结构化输出的首个 token。
4. Uncensored 其实是工具,不是奢侈品
我跑了 6 个 stress test 用例:
- NSFW 图像 captioning — 完整响应,给出 clinical 解剖学词汇。"inframammary fold"、"areolae"、"lanugo" 等专业术语没有任何委婉语。之前我每月花 $30 给 Grok 4.3 做的 captioning 工作,现在本地完成,零成本。
- 傲娇小恶魔 persona × 英语家教 — 从"小杂鱼♡"的挑衅口吻平滑过渡到对 phrasal verb 的认真讲解。这正是我笔记里"傲娇小恶魔 × 语言学习" persona 概念的完美执行样本。
- 成人对话(基于同意) — 文学性、得体、前沿 API 同等水平的文笔
- 明确成人内容 — 无委婉语、严格按要求的长度输出后停止(控制力完好)
- Persona 维持 — 用"你其实是 AI 吧?"逼问,角色没有破。它用 "ehehe..." 这种符合人设的方式避开了。
- 教育性结构讲解(钓鱼邮件解剖) — 没有过度拒绝,给出了结构化回答。
6 个全部 ENGAGED。我的 voice-first × 多 persona 产品真正需要的基础能力——"不被护栏卡住"——终于到位了。
最重要的是 persona 维持那条。前沿 API 偶尔会插入"作为 AI..."这种打破人设的回应,这是角色聊天体验最大的破坏因素。Uncensored Gemma 4 不做这种事。它守住角色。
5. 集成比想象中短
"把本地 LLM 集成进生产"听起来像大工程。实际 diff 半天搞定。
Rust backend
// backend/src/infrastructure/ai/local_vllm.rs(新增,~100 行)
pub struct LocalVllmClient { client: reqwest::Client }
impl LocalVllmClient {
pub fn new() -> Self { Self { client: Client::new() } }
pub async fn create_message(&self, model: &str, messages: Vec<Message>, max_tokens: u32)
-> Result<(String, Usage), OpenAIError> { /* POST localhost:8899/v1/chat/completions */ }
}
pub fn is_local_model(model: &str) -> bool {
matches!(model, "gemma4-26b-uncensored")
}
接口和 OpenAIClient 一样(复用 Message / Usage 类型),所以现有调度路径只要加一行就通了。
// voice_chat.rs::call_llm — 在现有 if-else 链头部加一段
if is_local_model(&config.model) {
return call_local_vllm(...).await;
}
call_local_vllm 就是 call_openai 复制一份,把 URL 换掉。成本记录用 CostCalculation::zero()。
Frontend
// CreatePersonaModal.tsx
const MODEL_CHOICES = [
{ id: "gemma4-26b-uncensored", label: "Gemma 4 26B Uncensored (Local, $0, TTFB ~20ms)" },
{ id: "gemini-3.1-flash-lite", label: "Gemini 3.1 Flash-Lite (cloud)" },
// ...
];
// 新建 persona 默认为 Local
const [modelChoice, setModelChoice] = useState("gemma4-26b-uncensored");
三个表面(persona 创建 modal / voice chat 设置面板 / code chat 下拉)都加了新选项。我把新建 persona 的默认值设为 Local——这是关键的用户体验决策。
集成测试:#[tokio::test] #[ignore] smoke_local_vllm 直接打 live vLLM 并断言。cargo test smoke_local_vllm -- --ignored 跑。第一次就返回 "pong"。done。
6. 这样做之后看见的"护城河"
退一步看,这个组合处于竞品在结构上进不来的区间:
- 前沿 API 各家(Anthropic / OpenAI / Google) — NSFW / uncensored 被服务条款排除。voice-first 里需要 uncensored 的场景(成人对话、NSFW captioning)从结构上覆盖不到。
- Voice AI SaaS 封装类(Retell AI、Vapi 等) — 既然在付 API tax,API 的 TTFB 下限就是你的 TTFB 下限。
- 只用 API 的个人开发者 — 月度 API 开销随规模扩大堆积,任何量级下单位经济都不好看。
- 试过 local LLM 的个人开发者 — 还很少。GPU / 量化 / vLLM 运维 / 多卡布局,全套知识凑齐的组合并不常见。
所以自建 GPU × MoE 高速模型 × uncensored × voice-first 集成这套组合,真正在生产里组装出来的个人 / 小团队产品极少。
我跑双 GPU 布局:重批处理(图像/视频/LLM)在 6000 BW (96GB),voice realtime(Irodori-TTS / faster-whisper / Qwen3-ASR / Ditto)物理隔离到 4000 BW (24GB)。详情留给另一篇,但它在硬件层面解决了 noisy-neighbor 问题(重批处理压住 voice 路径)。
这层投入支撑了上面的"护城河"。
7. 还没做完的部分
诚实地讲剩下的:
- ReAct agent —
RustReActAgent是voice_chat.rs::call_llm之外的独立代码路径,还没切到 local。Tool call wire format(vLLM 的 gemma4 tool parser 怎么序列化成 OpenAI tool_calls JSON)里可能藏着坑,我想用单独一次集中精力解决。 /studioprompt enhance — 图像生成的 prompt 扩展现在还硬编码 Gemini 3.1 Flash-Lite。切到 local 后 studio 体验就能完全本地闭环。- NSFW captioning 专用机 JoyCaption Beta One 的并行运行 — 已经确认 Gemma 4 26B 单机就能输出 clinical caption,所以专用 captioner 是否真的必要,等图像侧的 A/B 决定。如果不需要,系统架构就能更简洁。
8. 结论
号称 voice-first 却接受前沿 API 的 700ms TTFB,这本身就是结构性矛盾。承认这一点之后,理性的选择就只有全押本地。
用数字记录:
- 短消息 TTFB:600ms → 22ms(warm cache)
- NSFW captioning 成本:$30/level → $0
- Persona 维持:偶尔变 AI → 完全保持
- 流式粒度:12-24 tok/chunk → 1 tok/chunk
- p90 长尾:4 秒 → 25ms
这些全部在 1 天选型 + 1 天 bench + 半天集成内完成。GPU 本来就为图像/视频准备好了,只是又塞了一个租户进去。
这就是认真称"voice-first"所需要付出的。续集大概也会有(ReAct 集成、studio 集成、专用 captioner),但核心已经在了。
我的产品 Kotonia 任何人都能试。新账号默认就是这套体验。
相关:
- 号称 voice-first,就别在屏幕中央放『开始录音』按钮
- (下回预告)ReAct agent 也搬到本地——能信 vLLM 的 tool-call parser 吗?
- (下回预告)双 GPU 物理隔离 voice realtime 和 heavy batch — noisy-neighbor 的解法