The production path for our voice-roleplay product runs on Ditto lip-sync. The first-time wow is real. But after 2-3 turns, users start saying things like:
First time, I went "whoa." But once I'd cycled through the three or four images the persona has, it was kind of like, hmm. The screen does shift around, but the information density on it eventually converges.
That's the "2-3 turn avatar problem." Lip-sync keeps talking, but the user's attention decays. The diagnosis was already there. Lip-sync bandwidth and emotion bandwidth are not the same channel.
1. Why Ditto alone hits a ceiling
Ditto-TalkingHead produces minimal mouth / chin / head movement. The "they're really talking" realism is high. But Ditto itself doesn't shift facial expression dramatically — it's deliberately conservative to preserve identity.
That means "the range of emotions you can show is bounded by the number of stills you uploaded." If you set up N persona images and let the LLM swap them with {{SHOW: smile}}, N is your expressivity ceiling. And every image you add stretches the LLM's first-token latency linearly, because you're handing each one in as native inline_data.
Three requirements stack up against each other:
- Expressivity should grow as N × (emotion range)
- LLM first-call cost should stay flat
- Production cost (a solo dev's time) shouldn't blow up
Attacked head-on, it looks unsolvable. But the moment you accept that what the LLM sees ≠ what the user sees, the layer separation pops out cleanly. That's the asymmetric design at the core of this piece.
2. Asymmetric design — tags for the LLM, images for the frontend
The 13 variants for a persona, once generated, look like this:
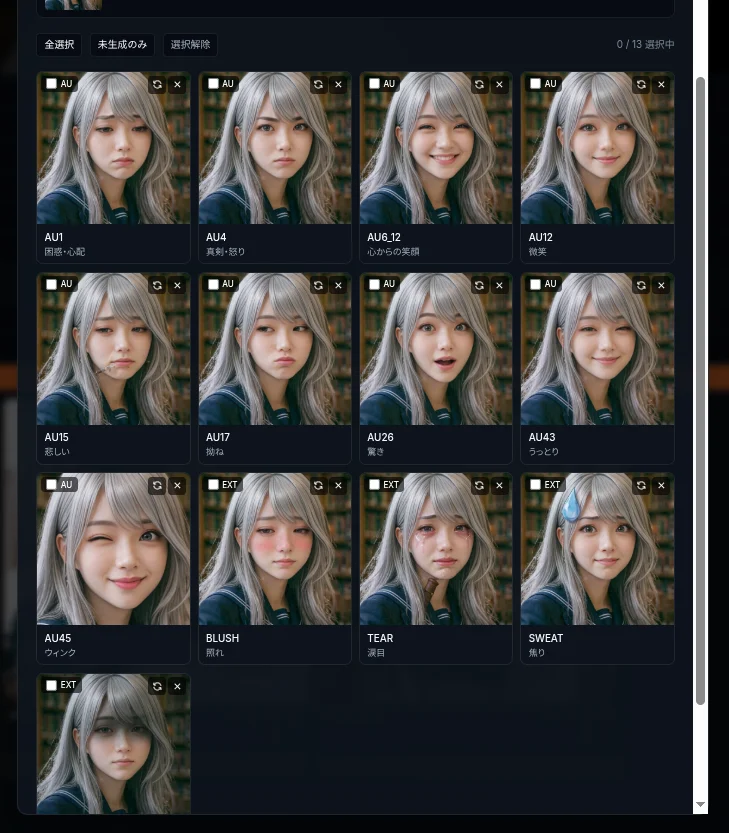
AU1 (concern) / AU4 (serious) / AU12 (subtle smile) / AU15 (sad) … the FACS vocabulary lines up, followed by BLUSH / TEAR / SWEAT / SHADOW as anime extensions. None of these 13 images is ever sent to the LLM. The LLM sees only "one base image" and "a list of codes."
In one sentence:
Pre-generate expression variants of the base persona image via I2I. Don't show the LLM the variant images. Inject only the list of tag strings into the system prompt. When the LLM emits
{{AU: <code>}}, the frontend looks up the variant by(media_id, code)to swap the rendered image and the Ditto avatar_id.
That keeps the LLM's context at "N base images + tag list (~30 tokens)". The user's screen scales to N × M variants. With M = 13 (the tag count we adopted), a persona with 5 base images becomes 65 emotional combinations on the user side.
The LLM's prefill cost goes up by ~30 tokens. None of the variant images cross the wire as native inline_data on Gemini / xAI / local vLLM, so image-token billing doesn't move.
This isn't avatar-specific. It's a general LLM-app design pattern: decide what the LLM sees and what the user sees as separate questions. Tool calling already does this (schema only), RAG does this (retrieved chunks only), function calls do this (name + args only). But once you cross into the UI layer, the default assumption flips to "the LLM sees what the user sees," and N starts pulling both LLM cost and user-experience ceiling in tandem. Pulling them apart on this one axis reclaims real headroom under the new context-pricing constraint.
The same pattern is the engine behind other decisions I've made: I built a terminal-native creative agent in a day frames the same idea as "the category between Code agent and Image gen is empty" — both come from "split the layers."
3. Why borrow FACS
If you try to design "expression codes" yourself, the namespace collapses. smile_shy / smile_evil / smile_proud multiplies fast, and the caller (= the LLM) gets worse at picking the right one.
Paul Ekman's FACS (Facial Action Coding System, 1970s) decomposes expressions into an anatomically orthogonal primitive set (AU1: inner brow raiser, AU12: lip corner puller, ...). Apple ARKit blendshapes and Unreal MetaHuman are descendants of the same lineage. A 50-year-old psychology vocabulary lands directly as the right API for today's AI avatar UX.
Using it as the LLM-facing surface gives you:
- A naming convention that holds together (
AU12/AU6+12/BLUSH) - Codes the LLM has seen everywhere in training data — zero-shot picks land cleanly
- A tuple that survives migration to full 3D avatars later
FACS intensities and AU combinations stay out of the MVP. Some FACS choices don't fit anime characters (it's grounded in real-human anatomy), so I added 4 anime extensions (BLUSH / TEAR / SWEAT / SHADOW) alongside 9 pure AU codes for a 13-tag catalog, single AU per variant, no compositions. "Eyes closed" maps to AU43; "upper half of the face goes dark in despair" has no FACS code, so the EXT line carries it.
4. Why frontier labs won't build this
This is the most interesting part, and it ties directly into the moat argument.
For OpenAI / Anthropic / Google, building avatar-specific UX has low ROI. Their core is foundation models; avatars are demo surface for multi-modality. "Layer an expression overlay on top of Ditto lip-sync" is too narrow an optimization to make their roadmap.
VC-backed avatar startups don't fit either. The BtoB players (Retell AI / Vapi-style) optimize for telephony and CX, where emotional theatrics are noise. BtoC character chat (Character.AI etc.) is text-first; avatars are secondary.
What's left is the UX bandwidth a user can visually feel "this isn't right" about — a band that has no business case for the frontier labs and gets de-prioritized inside VC-backed startups. So if an indie spends ~1 month layering on it, almost nobody is chasing them in.
That's a structural moat, and one I deliberately build into. The same logic appears in Features were already there — UX was the bottleneck: the recurring observation is that the moat isn't presence of features, it's the experience bandwidth around using them.
5. The other call: don't shy away from precomputation
"Pre-generate 13 variants" sounds heavy, but on a local GPU it's ~10s per image, ~2 minutes for 13. Tucks neatly behind a single button. Try to replace that with generate-on-the-fly inside the conversation, and a multi-second wall appears at every expression swap. The UX dies on contact.
A judgment I keep running into when polishing chat UX: where do you place the trade-off between "compute thinly on the fly" and "compute heavily up front"? Push heavy work inside the conversation loop, and the experience falls over. The LLM-app world is so steeped in "use the context window to generate anything dynamically" that the alternative — "batch-bake it ahead of time" — gets overlooked. For a product where users settle on a persona and keep it for a long time, the precompute side usually wins.
After generation, the same bytes go straight into Ditto's prepare and get registered under persona_media_{id}_au_{CODE}_ditto. The result: zero prepare latency on every in-conversation expression swap. A textbook case of "precomputation directly compounds into UX."
6. What changed, and how far this layer reaches
Six turns in, the "the screen's information density keeps converging" feeling is gone. Lip-sync bandwidth stayed the same; only the emotion bandwidth got its own layer.
The asymmetric-design instinct generalizes well past avatar UX. FACS-AU tuples drop straight into MetaHuman / Live2D / ARKit blendshapes, so the variant vocabulary I'm baking on a local GPU today survives migration to 3D / VR / AR avatars three years out. Near-term, the same axis stretches further:
- Combinational expressions (single AU now → composed AU6+12 etc. next)
- Coupling expression with speech (TTS speaker / prosody as part of the tuple)
- Posing / outfit / background as their own overlay axes
All of those keep the same shape: what the LLM sees is a tag; what the user sees is a pre-rendered, rich body.
Takeaways — design judgments to keep at the abstract layer
- Decomposing UX into separate bandwidths (lip-sync vs emotion) opens headroom where the surface looked saturated
- Splitting "what the LLM sees" from "what the user sees" asymmetrically lets you scale expressivity under context-window pricing. Tool calling and RAG do this by default; the UI layer doesn't, and it costs you
- Borrowing an established vocabulary (here: FACS) lets you skip few-shot setup — half a century of training data already encodes it. A 70s psychology framework lands as a 2026 avatar API
- Don't put heavy work inside the conversation loop. Bias toward batch-bake-ahead-of-time
- The UX band that frontier labs won't touch and VC startups deprioritize is exactly the band an indie can build a one-month moat in
Whether you're shipping an avatar chat product or any LLM-app, when "do everything inside the context window" stops scaling, try splitting layers. No one's ahead of you in this territory yet — there's still ground to claim by hand.
kotonia.ai runs all of this in the avatar-talk path today. Worth a try if you're curious.