音声ロールプレイの本番経路に Ditto リップシンクを使ってる。初回の wow は強い。けど 2-3 ターン回したユーザーが、こう言う:
最初すげえ、と思った。けど 2,3 回まわして設定してある画像をだいたい見終わったあと、うーん。動的ではあるけど画面の情報量は最終的に収束してしまうなあ。
これが「アバターチャットの 2-3 ターン問題」だった。リップシンクは喋り続けてるのに、ユーザーの注意は減衰していく。回答は出てた。リップシンクの帯域と、感情の帯域は、別物だった。
1. なぜ Ditto だけだと頭打ちになるか
Ditto-TalkingHead は口・あご・頭の最小動を生成する。「喋ってる感」のリアリティは高い。だが Ditto モデル自体は表情そのものは大きく変えない。顔の identity を壊さないよう、変化を意図的に抑えてある。
ここで詰むのは「感情の表現は持ち画像の枚数で決まる」という構造。N 枚のペルソナ画像を用意して {{SHOW: smile}} で切り替える設計だと、N が表現力の上限。そして N を増やすたびに LLM の初回推論レイテンシが線形に伸びる。なぜなら各画像をネイティブな inline_data として LLM に渡しているから。
ここに 3 つの相反する要件が立つ:
- 表現力は N × (感情のレンジ) で増えてほしい
- LLM の初回推論コストは横ばいで保ちたい
- 制作コスト (個人開発者の人手) は上げたくない
普通に攻めると無理ゲーに見える。だが「LLM に渡す情報 ≠ ユーザーが見る情報」というレイヤ分離をすると一気に解ける。これが今回の核となる非対称設計だ。
2. 非対称設計 — tag は LLM に、画像はフロントエンドに
実装したペルソナの 13 variant が並んだ状態は、こんな感じ:
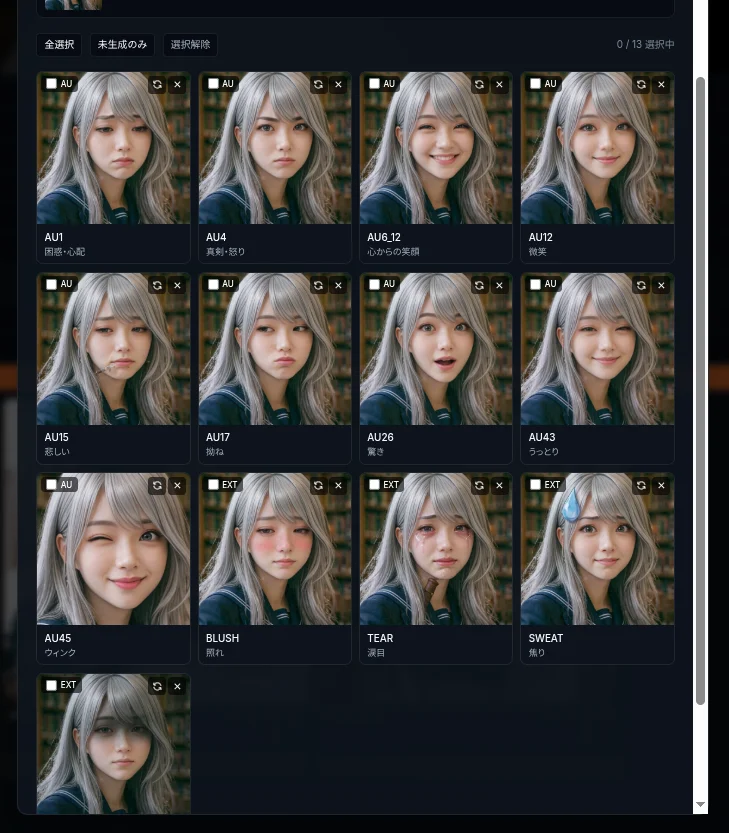
AU1 (困惑) / AU4 (真剣) / AU12 (微笑) / AU15 (悲しい) … と FACS の語彙が並び、BLUSH / TEAR / SWEAT / SHADOW がアニメ extension として続く。この 13 枚は LLM には 1 枚も渡らない。LLM が見るのは「基準画像 1 枚」と「コードのリスト」だけ。
設計を一言で言うと:
基準ペルソナ画像に紐づく表情バリエーションを 事前に I2I で生成しておく。LLM には variant 画像を渡さない。tag 文字列のリスト だけを system prompt に注入する。LLM が
{{AU: <code>}}を吐いたら、フロントエンドが(media_id, code)で variant 画像をルックアップして表示・Ditto avatar_id をスワップする。
これで LLM が見るコンテキストは「基準画像 N 枚 + tag list (~30 token)」のまま。ユーザーが見る画面は N × M バリエーション に増える。M = 13 (今回採用した tag 数) なら、画像 5 枚のペルソナで実質 65 通りの感情パレット。
LLM の prefill コストは tag 注入の ~30 token しか増えない。Gemini / xAI / local vLLM のどのモデルでも variant 画像はネイティブで渡らないので、画像トークン課金にも乗らない。
これは avatar 固有の話ではなく、LLM-app 全般に効く設計パターンだ。LLM に何を見せて、何を見せないかを、ユーザーが見るものとは別物として設計する。tool calling は schema だけ、RAG は retrieved chunk だけ、function call は名前と引数だけ、と既に普通に使われている。ところが UI 層になると「LLM が見たものをユーザーにそのまま見せる」発想がデフォルトになり、N に対する LLM コストとユーザー体験が同じ天井に張り付く。ここを分けるだけで、コンテキスト課金時代に表現力をスケールさせる余地が広がる。
同じ思想は CLI / agent 系の設計判断でも繰り返し当たっていて、例えば ターミナルで完結する creative agent を 1 日で作った話 で扱った「Code agent と Image gen の交差点が空いている」も、同じ「レイヤを分ける」発想の系譜にある。
3. なぜ FACS を借りるか
「表情コード」を独自に切ろうとすると、すぐ崩壊する。smile_shy / smile_evil / smile_proud ... と multiplicative に膨らみ、呼び出し側 (= LLM) は選びにくくなる。
Paul Ekman が 1970 年代に作った FACS (Facial Action Coding System) は、表情を解剖学的に直交した primitive set (AU1: inner brow raiser, AU12: lip corner puller, ...) に分解する。Apple ARKit の blendshape も、Unreal MetaHuman も、この系譜の発展形だ。50 年前の心理学の用語体系が、今の AI avatar の UX の語彙としてそのまま降りてくる。
これを LLM-facing の API として使うと、
- 命名規約が自然 (
AU12/AU6+12/BLUSH) - LLM が訓練データで山ほど見ている — few-shot ゼロで適切に選ぶ
- 将来 3D アバターに移行しても tuple がそのまま使える
FACS の literal な強度や AU の組み合わせは MVP では切る。アニメ調キャラには合わない部分 (実写顔の解剖学準拠) もあるので、純 AU 9 種 + アニメ extension 4 種 (BLUSH / TEAR / SWEAT / SHADOW) の 計 13 tag で MVP を組んだ。アニメで「目をつぶる」は AU43 でいいが、「顔の上半分が真っ黒になる落ち込み」は AU には無いので extension として足す。
4. なぜフロンティアラボはこれを作らないか
ここが一番面白い部分で、moat の議論に直結する。
OpenAI / Anthropic / Google にとって、avatar 専用 UX を作る ROI は低い。彼らの主力は基盤モデルそのもので、avatar はマルチモーダルのデモ用途。「Ditto のリップシンクの上に表情オーバーレイ層を被せる」みたいなニッチな最適化は、彼らの製品ロードマップに乗らない。
VC バック の avatar 系スタートアップは別の理由で乗りにくい。BtoB 営業 (Retell AI / Vapi 系) は telephony や CX に最適化されていて、感情の演出はむしろノイズ。BtoC のキャラクター chat (Character.AI 等) はテキストファーストで、avatar は二次的。
ここで残るのが、ユーザーが目で見て「これ違うわ」と気付ける UX 帯域 だ。フロンティアラボはこの帯域に投資する経済合理性が薄い。VC バック企業もコア事業の優先度に押される。すると、indie が 1 ヶ月くらいかけて積めば、誰も追ってこない領域になる。
これは構造的な moat で、自分が積極的に作っている類のものだ。同じ系の議論は 個人開発で機能はあるのに使われてない問題、UI 分割で解いた でも扱っているが、共通しているのは「機能の有無ではなく、機能を使うときの体験帯域が moat になる」という認識。
5. 事前計算を厭わない設計、というもう一つの判断
「事前に 13 枚生成」と書くと重く聞こえるが、ローカル GPU で 1 枚 ~10s、13 枚で 2 分。1 ボタンに収まる。これを 会話中に generate-on-the-fly に置き換えると、talking 中の表情切替に毎回数秒の壁が立ち、UX の決定的な部分が崩れる。
対話 UX を磨くときの繰り返し当たる判断は 「JIT で薄く計算 vs 事前に厚く計算」のトレードオフをどこに置くか で、対話ループの内側に重い計算を入れた瞬間に体験は死ぬ。LLM-app 全般で「context window で動的に何でも作る」発想が強い分、「事前にバッチで焼く」選択肢が見落とされやすい。一度ペルソナを作ったら長く使う製品なら、事前バッチ側が勝ちやすい。
生成したら即その bytes で Ditto の prepare まで焼いておく (persona_media_{id}_au_{CODE}_ditto 形式の avatar_id で登録)。これで会話中の表情切替が prepare レイテンシ 0 で動く。「事前計算を厭わない」が UX に直結する典型例。
6. 体感の変化と、別レイヤへの汎用性
5-6 ターン回しても「画面の情報量が収束する感じ」が消えた。リップシンクの帯域はそのまま、感情の帯域だけ別レイヤで増やした効果。
非対称設計の発想は、avatar UX の枠を越えて長く効く。FACS-AU の tuple はそのまま MetaHuman / Live2D / ARKit の blendshape にも投げられるので、今ローカル GPU で焼き込んでる variant の語彙が、3 年後の 3D / VR / AR avatar に持ち込める。直近の伸びしろも同じ系で並ぶ:
- 表情の組み合わせ (単一 AU → AU6+12 のような合成へ拡張)
- 表情と発話の連動 (TTS speaker や prosody を tag tuple に持たせる)
- 体勢・服装・背景の overlay 化 (avatar とは別軸の非対称設計を重ねる)
どれも「LLM に渡すのは tag、ユーザーに見せるのは事前計算済みのリッチな実体」の構造を保ったまま拡張できる。
まとめ — 抽象側に置きたい設計判断
- リップシンクの帯域 ≠ 感情の帯域、というように UX の中で帯域を分解する と、頭打ちに見える局面の伸びしろが立つ
- 「LLM に渡す情報」と「ユーザーが見る情報」を 非対称に切る と、コンテキスト課金時代に表現力をスケールできる。tool calling / RAG で当然のように使われてる発想を、UI レイヤにも適用する
- 既存の用語体系 (今回は FACS) を借りると、LLM の訓練データに乗ってる分 few-shot ゼロで使える。50 年前の心理学が今の avatar UX の語彙としてそのまま降りてくる
- 対話の内側に重い計算を入れない。事前バッチ側に倒す 設計判断を意図的に取る
- フロンティアラボがやらない / VC バック企業も優先順位的にやらない UX 帯域は、indie が 1 ヶ月で積める moat になる
avatar チャットや voice エージェントに限らず、LLM-app の設計で「context window で全部やる」発想に詰まったら、層を分けてみる。誰も先に進んでないからこそ、まだ手で積める領域がある。
kotonia.ai のアバタートーク経路で実装稼働中。気が向いたら触ってみてほしい。