我们的语音角色扮演产品在生产路径上跑着 Ditto 口型同步。第一次的 wow 是真的有。可只要转过 2-3 轮,用户就会这样说:
第一眼是「哇」。但是把这个人物设定好的那几张图轮流看完之后,就只剩下「嗯…」了。画面确实在动,但屏幕上的信息密度最终还是收敛了。
这就是「avatar 聊天的 2-3 轮问题」。口型继续在说话,用户的注意力却在衰减。诊断书早就写好了:口型同步的带宽,和情感的带宽,本来就不是同一条信道。
1. 为什么只用 Ditto 会撞天花板
Ditto-TalkingHead 生成最小限度的嘴部 / 下颌 / 头部动作。「真的在说话」的真实感很强。但 Ditto 本身并不会大幅度改变表情——为了不破坏角色的 identity,模型在表情上是刻意保守的。
由此产生的结构问题是:「情感表现力的上限 = 你上传了多少张图」。如果只准备 N 张角色图、用 {{SHOW: smile}} 让 LLM 切换,那 N 就是表现力的天花板。而且 N 增加一张,LLM 的首次推理延迟就线性多一段——因为每张图都是作为原生 inline_data 喂进去的。
三个要求在这里互相打架:
- 表现力应该按照 N ×(情感范围)扩展
- LLM 首次调用的成本要保持横盘
- 制作成本(独立开发者的人手)不能爆炸
正面硬刚看起来是个无解局。但只要承认「LLM 看到的东西 ≠ 用户看到的东西」这件事,分层方案就突然变干净了。这就是本文的核心非对称设计。
2. 非对称设计 — tag 给 LLM,图像给前端
一个 persona 完成 13 个变体之后,长这样:
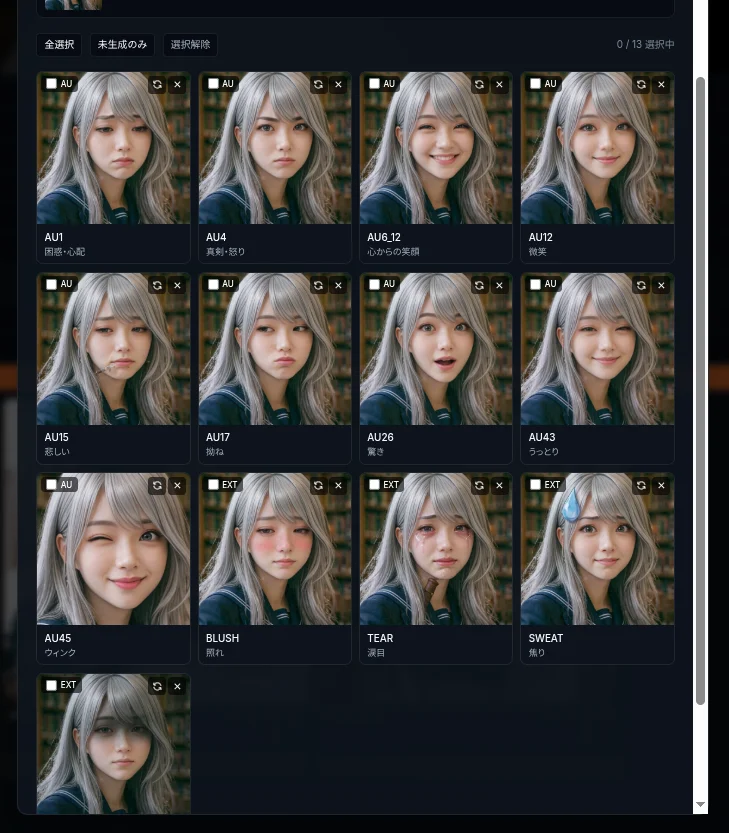
AU1(困惑)/ AU4(严肃)/ AU12(浅笑)/ AU15(悲伤)……FACS 词汇一字排开,后面跟着 BLUSH / TEAR / SWEAT / SHADOW 这些动画风扩展。这 13 张图,一张都不会送进 LLM。LLM 能看到的只有「一张基准图」和「代码清单」。
设计一句话概括:
提前用 I2I 给基准角色图预生成各种表情变体。这些变体图绝对不给 LLM 看。 在系统提示里注入的只是 tag 字符串的清单。当 LLM 吐出
{{AU: <code>}}时,前端按(media_id, code)查表,切换展示的图片和 Ditto 的 avatar_id。
这样 LLM 看到的上下文还是「N 张基准图 + tag 清单(约 30 token)」。用户看到的画面则放大到 N × M 个变体。M = 13(这次采用的 tag 数)的话,5 张基准图的 persona 就能在用户侧形成 65 种情感组合。
LLM 的 prefill 成本只增加约 30 token。在 Gemini / xAI / 本地 vLLM 任何一个模型上,变体图都不会作为 inline_data 上线,所以图像 token 计费也不会动。
这件事不只对 avatar 有用,是一个适用于 LLM-app 整体的设计模式:「让 LLM 看什么、让用户看什么」要作为两个独立问题来设计。tool calling 已经这样做(只给 schema),RAG 已经这样做(只给检索片段),function call 也是(只给名字和参数)。但一旦进到 UI 层,默认假设就反转成「LLM 看到的东西就是用户看到的东西」,于是 N 同时拉高 LLM 成本和用户体验天花板。把这两件事在某一根轴上拆开,就能在上下文计费时代腾出真实的扩展空间。
我重复在用的也是同一种思路:一天写出一个终端原生的 creative agent 里讨论的「Code agent 和 Image gen 的交叉点是空的」,本质上也是「把层拆开」。
3. 为什么借用 FACS
如果你尝试自己定义「表情代码」,命名空间会很快崩坏。smile_shy / smile_evil / smile_proud 这样的乘法式扩张越来越多,调用方(也就是 LLM)反而越来越难选对。
Paul Ekman 在 1970 年代提出的 FACS(Facial Action Coding System)把表情分解成 解剖学上正交的 primitive 集合(AU1: inner brow raiser、AU12: lip corner puller……)。Apple ARKit blendshape 和 Unreal MetaHuman 都是这一谱系的后辈。50 年前的心理学词汇体系,原封不动地成了今天的 AI avatar UX 的 API。
把它作为 LLM-facing 的接口,可以得到:
- 命名规则稳得住(
AU12/AU6+12/BLUSH) - LLM 在训练数据里见过无数次 — zero-shot 就能选得很准
- tuple 在将来迁移到 3D avatar 时也不报废
literal 的 AU 强度和 AU 组合在 MVP 阶段先砍掉。FACS 有些部分(基于真人脸的解剖学)和动画风角色合不来,所以在纯 AU 9 种之外加了 4 种动画风扩展(BLUSH / TEAR / SWEAT / SHADOW),凑成 13 个 tag 的目录,每个变体只对应一个 AU,不做组合。「闭眼」可以归到 AU43;「情绪低落时整张脸的上半部分变黑」这种动画风套路 FACS 没有,所以走 EXT 这条线补。
4. 为什么前沿大厂不会做这个
这部分最有意思,直接连接到护城河的讨论。
对 OpenAI / Anthropic / Google 来说,做 avatar 专用 UX 的 ROI 很低。他们的核心是基础模型本身,avatar 只是多模态的演示场景。「在 Ditto 口型同步上再叠一层表情 overlay」这种太窄的优化,根本上不了他们的产品路线图。
VC 撑的 avatar 创业公司也没办法做。BtoB 路线(Retell AI / Vapi 系)是为电话和 CX 优化的,情感戏的演出反而是噪声。BtoC 的角色聊天(Character.AI 等)是 text-first,avatar 是次要的。
剩下来的是 用户用眼睛能感觉到「这不对劲」的 UX 带宽。前沿大厂在这条带宽上的投资经济合理性很弱,VC 公司在核心业务的优先级压力下也会被往后排。结果就是,indie 花一个月在上面堆,几乎没人在后面追。
这是一种结构性的护城河,也是我有意去搭建的那一类。原本就具备的功能,瓶颈其实是 UX 也在讨论同样的事——反复出现的认识是:护城河不是「有没有功能」,而是「使用功能时的体验带宽」。
5. 另一个判断 — 不要嫌弃事先计算
「事先生成 13 张图」听起来很重,但在本地 GPU 上 1 张约 10 秒,13 张 2 分钟。一个按钮就能搞定。换成 在对话过程中 generate-on-the-fly,每次切换表情时都会出现一道几秒的墙,UX 就死了。
打磨对话 UX 的时候我反复在做的判断是:「JIT 薄薄计算」和「事先厚厚计算」的权衡放在哪里。在对话循环的内部塞重计算,体验立刻塌掉。LLM-app 圈里「context window 里动态搞定一切」的氛围太重,「事先批量烤出来」这种选项往往被漏掉。但只要这是一个用户选定 persona 后会长期使用的产品,事先批量这一侧通常更划算。
生成后顺手把同一段 bytes 喂进 Ditto 的 prepare,按 persona_media_{id}_au_{CODE}_ditto 这种格式注册。这样对话中切换表情时的 prepare 延迟就是 0。「不嫌弃事先计算」直接复利到 UX 的典型案例。
6. 体感的变化,与这一层的通用性
跑到第 5、6 轮,「画面信息密度在收敛」的感觉消失了。口型同步的带宽没变,只有情感的带宽被另起一层加宽。
非对称设计的发想,远不止 avatar UX 这一块能用。FACS-AU 的 tuple 可以直接喂进 MetaHuman / Live2D / ARKit 的 blendshape,所以今天在本地 GPU 上烤出来的变体词汇,3 年后照样能搬到 3D / VR / AR 的 avatar 上。短期内的扩展也在同一根轴上排好:
- 表情组合(现在是单一 AU → 下一步合成 AU6+12 这种)
- 表情与发声的联动(把 TTS speaker / prosody 也带进 tuple)
- 体态、服装、背景也做成各自的 overlay 轴
全都能保持「LLM 看到的是 tag,用户看到的是事先烤好的丰富实体」这个结构来扩展。
总结 — 想放在抽象层的设计判断
- 把 UX 拆成多个 带宽(口型同步 vs 情感),看起来到顶的局面就能腾出新空间
- 把「LLM 看到的」和「用户看到的」做非对称切分,可以在 context window 计费时代继续扩展表现力。tool calling 和 RAG 默认这样做;UI 层还在用老办法,代价是性能
- 借用已有的词汇体系(这次是 FACS)就能 省掉 few-shot 设置——半个世纪的训练数据早就编码好了。70 年代的心理学框架,恰好是 2026 年的 avatar API
- 不要把重活儿放进对话循环里。倾向于「事先批量烤」
- 前沿大厂不碰、VC 公司也排不到优先级 的那条 UX 带宽,正好是 indie 用一个月就能筑起 护城河 的地方
不管你是在做 avatar 聊天还是别的 LLM-app,当「context window 里搞定一切」开始无法扩展的时候,试着拆分层。前面还没人占位,亲手堆几座山也来得及。
kotonia.ai 上 avatar 对话路径里这些都已经跑起来了。有兴趣的话欢迎试试。