TL;DR
HiDream-O1-Image(2026-05 发布,OpenWeight 8B,在 Artificial Analysis Text-to-Image Arena 中排名第 8 的 T2I 模型)的 skeleton(= 试穿)模式下,出现了“姿势不听话”的现象。我们通过 8 种模式 + 3 种布局模式进行了实证基准测试,结果发现了 3 个反直觉的事实。
- 传入 openpose 参考图,反而会导致姿势固化在参考图的构图上。当需要动态姿势时,移除 openpose 参考图,通过 prompt 来指示效果更强。
- 当参考图达到 6 张(face+bg+pose+parts 的完整套装)时,单张参考图的分辨率会降至 768px,导致细节崩坏。保持在 3-4 张以维持 1024px 分辨率,质量更高。
- README 推荐的
shift=1.0专用于试穿。若要更换姿势或服装,应使用shift=2.0-2.5;若要彻底重塑场景,应使用shift=3.0。
阅读 pipeline.py 后发现,“skeleton 模式没有专用处理”。/generate/skeleton 和 /generate/ip 在内部完全走同一条多参考图路径,参考图是“面部/背景/openpose/服装”中的哪一个,只能通过提示词来传达。这就是该现象的根本原因。
动机
在本地 GPU (RTX PRO 6000 Blackwell, 96 GB) 上常驻运行 HiDream-O1-Image 并集成到自有平台时,我们遇到了 skeleton(试穿)模式不遵循提示词指令的问题。即使输入“举起双手跳起来”,也只能得到一张站立的试穿照片。
我们曾怀疑是护栏(如 NSFW 审查或安全策略)的问题,并用 safety|nsfw|guard|filter|moderate|censor 进行 grep 搜索,但 HiDream 的代码库中完全没有这类机制(只命中了一个 CSS 的 backdrop-filter: blur)。正如其 MIT 许可证的 OpenWeight 模型所言,它没有审查机制。
那么问题出在哪里?我们一边阅读 pipeline.py,一边在实机上测试了 8+3 种模式,结果如下。
环境
- GPU: NVIDIA RTX PRO 6000 Blackwell Max-Q (96 GB VRAM)
- PyTorch: 2.12.0 + CUDA 13.0
- flash-attn: 2.8.3 (sm_120 限定构建)
- 模型: HiDream-O1-Image Full (8B, bf16, ~16.4 GiB 常驻)
- 推理服务器: 自建 Python BaseHTTPRequestHandler 常驻 (port 8895)
- 分辨率: pipeline 内部桶机制强制对齐至 2048×2048
50 步生成单张图片的实测数据:
| 模式 | 时间 | iter speed |
|---|---|---|
| t2i (无参考图) | ~33s | 1.52 it/s |
| edit (1 张参考图) | ~76s | 1.01 it/s |
| skeleton (多参考图) | ~84s | 1.34 it/s |
| ip (多参考图) | ~76s | 1.81 it/s |
| layout (多参考图 + bbox) | ~83s | 1.21 it/s |
验证素材
HiDream 仓库的 assets/IP_skeleton/ 中包含用于 skeleton 的完整素材集。我们将其作为原始素材使用。
| 参考图 | 内容 | 预期用途 |
|---|---|---|
 | 人物面部照片 | 身份参考 |
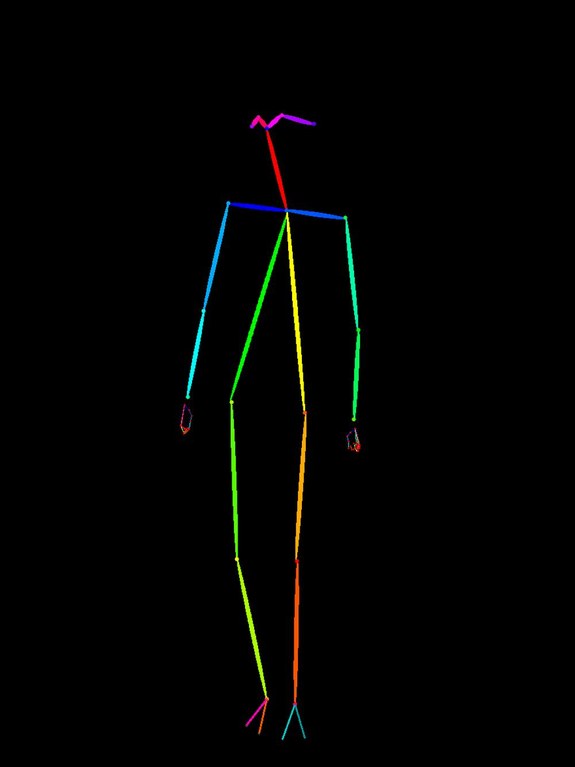 | OpenPose 格式的火柴人 | 姿势指定 |
 | 背景照片(室内) | 场景参考 |
  | 服装部件(毛衣、靴子) | 服装参考 |
8 种模式 skeleton 基准测试
每种模式都调用 /api/studio/skeleton(即使用相当于 skeleton 模式的参数调用 HiDream 的 generate_image())。除 shift 和 guidance_scale 外,其他参数固定(50 steps, seed=42)。
A — 基线(README 默认,投入全部 6 张参考图)
curl -X POST http://localhost:8895/generate/skeleton \
-H 'Content-Type: application/json' \
-d '{
"prompt": "Create a realistic try-on image of the person wearing the provided clothing.",
"ref_image_paths": ["face","bg","openpose","part_1","part_2","part_3"],
"shift": 1.0, "seed": 42
}'

结果: 原背景参考图中的墙壁和架子被完全再现。姿势也如 openpose 参考图一样是站立的。作为试穿效果很忠实,但“动态”和“自由度”为零。
B — 提高 shift(同样 6 张参考图,shift=2.5)
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "Create a realistic try-on image of the person wearing the provided clothing.",
"ref_image_paths": ["face","bg","openpose","part_1","part_2","part_3"],
"shift": 2.5, "seed": 42
}'

结果: 架子变淡了,人物设计有微小的变化。背景依然固化在背景参考图上。仅靠提高 shift 无法完全摆脱背景参考图的牵引力。
C — 同时提高 guidance(shift=2.5, guidance=7.0)
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "...",
"ref_image_paths": [...6 refs...],
"shift": 2.5, "guidance_scale": 7.0, "seed": 42
}'

结果: 项链变形为奇怪的形状。提高 guidance 会开始产生伪影。Full 模型的最佳点是 5.0,7.0 过高了。
D — 将参考图缩减至 3 张(face + openpose + sweater)+ 具体提示词
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "A young Asian woman wearing a gray oversized sweater dress, standing in a relaxed pose, full body shot, soft natural lighting, white studio background.",
"ref_image_paths": ["face","openpose","part_1"],
"shift": 2.0, "seed": 42
}'

结果: 大幅改善。背景变为纯白影棚,服装得以维持,姿势也自然。移除背景参考图的效果显著。这才是“正确的试穿”输出。
E — 4 张参考图 + 明确参考图编号的提示词
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "Full body try-on photograph. Subject: the woman from image 1. Pose: identical to the skeleton in image 2. Wearing: the gray oversized knit sweater dress shown in image 3, brown leather ankle boots shown in image 4. Studio lighting, plain background.",
"ref_image_paths": ["face","openpose","part_1","part_2"],
"shift": 2.0, "seed": 42
}'

结果: 与 D 质量相当,靴子也有所体现(略显保守)。明确参考图编号是有效的,但并非决定性差异。
F — 移除 openpose,通过 prompt 指定姿势
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "Full body photograph of the woman wearing the gray sweater dress and brown ankle boots, dynamic dancing pose with both arms raised above her head, joyful expression, photo studio with white seamless background, professional lighting.",
"ref_image_paths": ["face","part_1","part_2"],
"shift": 2.5, "seed": 42
}'

结果: 🏆 成功实现双手举起跳跃。无 openpose 参考图 + 提示词中的动态指令,首次生成了动态姿势。这证实了,加入 openpose 参考图会导致提示词失效。
G — 仅 1 张面部参考图 + 自由提示词(服装也完全更换)
/generate/skeleton 有最少 2 张参考图的验证,因此通过 /generate/ip 调用:
curl -X POST http://localhost:8895/generate/ip -d '{
"prompt": "Elegant full-body portrait of the woman wearing a vibrant red sequined evening gown with a thigh-high slit, standing confidently with one hand on her hip, soft cinematic lighting, dark blurred background.",
"ref_image_paths": ["face"],
"shift": 3.0, "seed": 42
}'

结果: 🏆 完美生成红色性感礼服。面部一致性得以保持,其他一切自由发挥。1 张面部参考图 + shift 3.0 是最大自由度的模式。
H — 与 E 相同设置,seed=999(确认随机性)
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "Full body try-on photograph. ...",
"ref_image_paths": ["face","openpose","part_1","part_2"],
"shift": 2.0, "seed": 999
}'

结果: 与 E 有细微差别,靴子的棕色更明显。调整 seed 对细节优化有效,因此在实际应用中,通常的做法是尝试 3-5 个 seed 值,从中择优。
也看看布局模式(附赠 3 种模式)
layout_bboxes 本应能通过相对坐标 [x1, x2, y1, y2] 指定“多个主体在图像中的位置”。我们确认了其实际行为。
输入的参考图是两个人的面部照片(女、男):


L1 — 并排(女性 left, 男性 right)
"layout_bboxes": "[[0.0,0.5,0.1,0.95],[0.5,1.0,0.1,0.95]]"

结果: 左右位置互换了(男性 left, 女性 right)。参考图顺序与 bbox 顺序的对应关系无法保证。
L2 — 上下分割(女性 top, 男性 bottom)
"layout_bboxes": "[[0.2,0.8,0.0,0.5],[0.2,0.8,0.5,1.0]]"

结果: 女性在远处,男性在近处,形成了层次构图。它被解释为“纵深”而非“上下”。
L3 — 大小(女性 大、男性 小)
"layout_bboxes": "[[0.1,0.65,0.1,0.95],[0.7,0.97,0.05,0.45]]"

结果: 两者尺寸几乎相同,并排站立。bbox 的尺寸指定无效。
→ 将 Layout 模式理解为 “生成集体照的提示” 才是正确的。它并非 Photoshop 式的精确布局。它仅限于为将多个主体放入一张图片提供构图提示,不要对坐标精度抱有期待。
为什么会这样 — 阅读 pipeline.py
支配 HiDream 行为的是 models/pipeline.py 中的 generate_image() 函数。通过阅读,我们发现了 3 个结构性问题:
1. 参考图数量增加会导致单张分辨率下降
pipeline.py:198-202:
if K == 1: max_size = max(height, width) # 2048
elif K == 2: max_size = max(height, width) * 48 // 64 # 1536
elif K <= 4: max_size = max(height, width) // 2 # 1024
elif K <= 8: max_size = max(height, width) * 24 // 64 # 768
else: max_size = max(height, width) // 4 # 512
投入 6 张参考图时,每张参考图会被压缩至 768px。openpose 的细线、服装的精细图案、面部表情都会瞬间变得模糊。缩减至 3-4 张可保持在 1024px,细节更清晰。
2. skeleton 模式没有专用处理
查看 pipeline.py:178-275,不存在针对 skeleton 的特殊分支。/generate/skeleton 和 /generate/ip 在内部完全走同一条多参考图路径:
content = [{"type": "image"} for _ in range(K)]
content.append({"type": "text", "text": caption})
messages = [{"role": "user", "content": content}]
“这是面部”、“这是 openpose”、“这是服装部件”这类角色提示不会传递给模型。它们全部被当作“仅仅是 K 张参考图像”并行处理。要传达其角色,只能通过提示词文本来明确说明。
这就是“openpose 参考图不如 prompt 强大”现象的本质。openpose 参考图最多被当作“图像某处有这种线条画”的参考来处理,其作为姿势指定器的角色并未被明确传达。另一方面,提示词中的 dynamic dancing pose with both arms raised 则作为明确的动词和名词在词汇层面被处理。
3. shift 参数的作用
shift 用于调整调度器的噪声调度强度。体感如下:
- 1.0 = 对参考图构图最大程度忠实,自由度为零 → 专用于试穿
- 2.0-2.5 = 实用范围,允许偏离参考图
- 3.0+ = 几乎自由生成,参考图仅用于身份参考
README 在 IP/Skeleton/Layout 中推荐 1.0,是假设了“典型的试穿、角色一致性”场景。若想生成与参考图不同的构图,如“姿势切换”、“服装更换”、“场景创建”,则必须使用 2.0 以上。
按用途分类的最佳实践(已实证总结)
| 目标 | endpoint | refs | shift | 备注 |
|---|---|---|---|---|
| 忠实于原场景的试穿 | /skeleton | 6 (face+bg+pose+3parts) | 1.0 | README 默认。对所有参考图都高度忠实 |
| 维持服装 + 自然的站姿 | /skeleton | 3-4 (face+服装,移除 bg/pose) | 2.0 | 移除背景参考图会变为白色影棚,减少参考图数量可使单张分辨率从 768 提升至 1024 |
| 大胆切换姿势 | /skeleton | 3 (移除 openpose) | 2.5 | 提示词比 openpose 参考图更能支配动作 |
| 完全更换服装 | /ip | 1 (仅面部) | 3.0 | 最大自由度,仅保持面部。skeleton 模式有最少 2 张参考图的验证,会被拒绝 |
| 集体照 | /layout | 多人参考图 + 粗略的 bbox | 1.0 | bbox 是粗略的构图提示,尺寸层级无效,参考图顺序与 bbox 顺序的对应关系不保证 |
| 细节优化 | 相同设置 | 相同 | 相同 | 尝试 3-5 个 seed 值,择优选取 |
总结
如果将 HiDream-O1-Image 的 skeleton 模式当作“试穿模拟器”来使用,即使没有护栏,也会产生“不听话”的体验。原因不在于模型或政策,而在于 pipeline 的结构性问题(参考图数量导致分辨率下降 + skeleton 无专用处理 + shift 对参考图的牵引力)。
实用的折衷方案:
- 试穿 = 6 张参考图全投入 + shift 1.0(遵循 README 默认)
- 想改变动作 = 移除 openpose 参考图 + 提示词中使用动词指定 + shift 2.5
- 完全自由的场景创建 = 1 张面部参考图 + shift 3.0 + 通过
/ip调用
对于 Layout 模式,若能将其理解为“集体照提示”而非“精确 bbox”,就不会产生预期偏差。
基准测试所用的素材和命令可直接使用 HiDream-O1-Image 仓库 中的 assets/IP_skeleton/ 和 assets/IP_layout/,因此可以复现。只需改变 shift 和参考图数量,行为就会发生巨大变化,将其作为一个试验场,通过反复试错来掌握手感是最快的方法。
补记:尝试改变 openpose 参考图 — “prompt 总是更强”是有条件的
文章发布后,我们追加验证了“如果传入不同形状的 openpose 会怎样”,结果发现需要修正上述结论。
将加工过的 openpose 作为参考图传入(4 种模式)
我们将原始的 openpose 图像(0.openpose.jpg,站立姿势)进行上下翻转和 90 度旋转,加工成“不自然的姿势”,并在提示词中指定普通的站立姿势,观察其行为。
| 加工 | 图像 |
|---|---|
| 上下翻转 (倒立) |  |
| 90 度旋转 (横卧) |  |
| 测试 | openpose 参考图 | 提示词 | 结果 |
|---|---|---|---|
| O1 基线 | 原始 (站立姿势) | 站立姿势 |  符合预期的站立姿势 符合预期的站立姿势 |
| O2 | 🙃 上下翻转 | 站立姿势 |  站立姿势 (完全无视 openpose,提示词胜出) 站立姿势 (完全无视 openpose,提示词胜出) |
| O3 | 🙃 上下翻转 | 跳跃 |  双手举起跳跃 (无视 openpose,提示词胜出) 双手举起跳跃 (无视 openpose,提示词胜出) |
| O4 | ↻ 90 度旋转 | 站立姿势 |  站立姿势,但画布本身旋转了 90 度! 站立姿势,但画布本身旋转了 90 度! |
至此,我们有了新发现:“模型会拒绝不自然的参考图并倾向于提示词”,“但整体的构图方向(纵向 vs 横向)会受到参考图影响”。
然而,如果参考图足够戏剧化且提示词未指定姿势,参考图则完全胜出
我们使用 HiDream 的 T2I 生成了“色彩缤纷的解剖学骨架,双臂 T 字形展开,单腿高高抬起,呈树式瑜伽姿势”,并将其作为参考图输入:
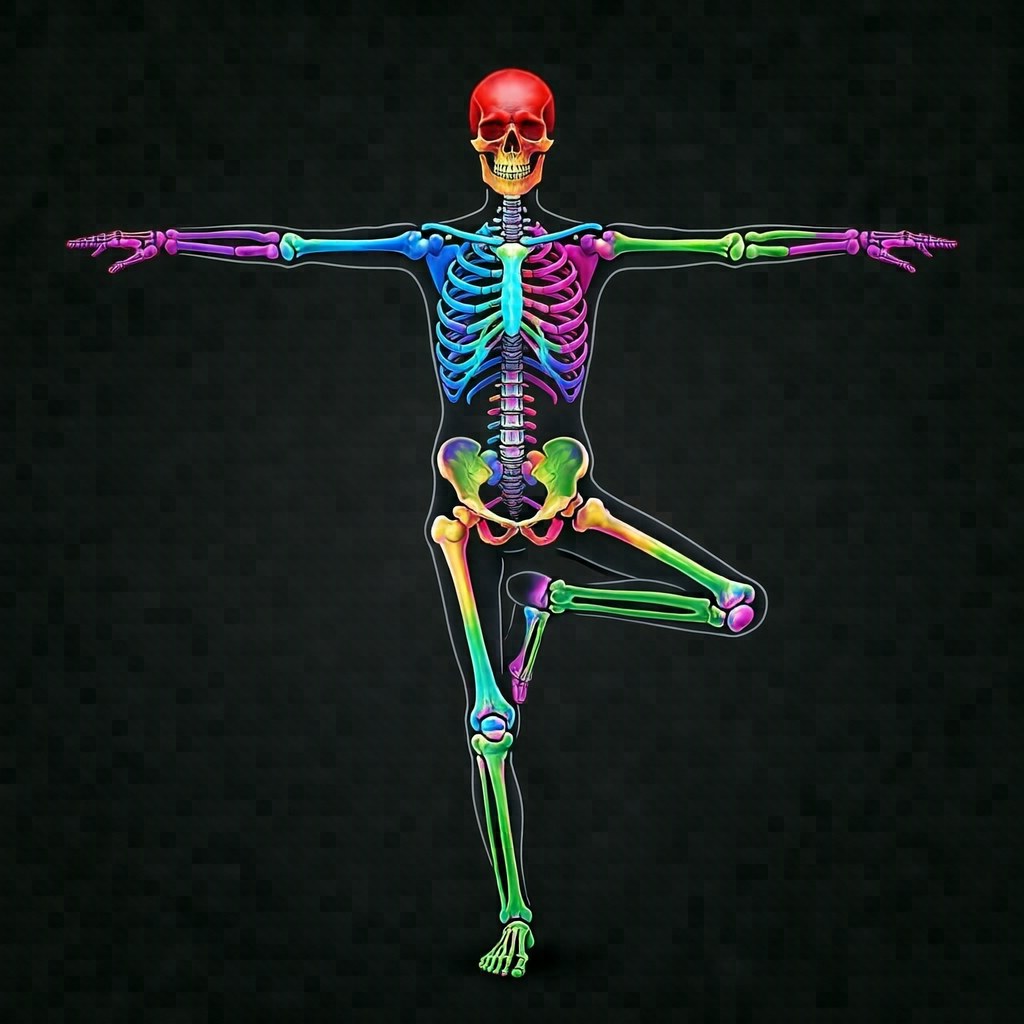
提示词完全不提及姿势,仅描述主体和服装:
curl -X POST http://localhost:8895/generate/skeleton -d '{
"prompt": "Full body photograph of a young Asian woman wearing a gray sweater dress, soft natural lighting, white studio background.",
"ref_image_paths": ["face","SYNTHETIC_WARRIOR_SKELETON","sweater"],
"shift": 1.0, "seed": 42
}'
结果:

完美再现了树式瑜伽姿势 — 双臂 T 字形 + 单腿站立,与参考图的骨架完全一致。
修正后的结论(3 条规则)
综合全部 12 种模式,HiDream 的实际行为如下:
- 如果提示词提及了姿势,那它就是第一优先级 — 即使与参考图矛盾,提示词也会胜出
- 如果提示词未提及姿势,则采用参考图的姿势 — 参考图越戏剧化,效果越明显
- 如果参考图被判定为“不自然”(如倒立骨架等),模型会回退到默认姿势 — 但整体的构图方向有时会得到反映
也就是说,“openpose 参考图实际上无效”这种说法有些言过其实,更准确的说法是“在提示词描述姿势的场景下,参考图会被覆盖”。本文的 8 种模式属于“提示词指定动态姿势的场景”,因此结果看起来像是“openpose 参考图无能为力”。
对实际应用的影响
- 想完全控制姿势时:不在提示词中写姿势 + 输入戏剧化的 openpose / skeleton 参考图 → 参考图的姿势会被转移过来
- 想通过提示词指示动作时:可以移除 openpose 参考图(即使加入参考图,也会被提示词覆盖)
- 当参考图和提示词矛盾时:提示词胜出(加入参考图也是徒劳)
关键在于,可以通过是否在提示词中提及姿势来切换“姿势的来源”。如果想使用 openpose 参考图,诀窍就是“不要在提示词中写姿势”。
相关链接:
- HiDream-O1-Image: https://huggingface.co/HiDream-ai/HiDream-O1-Image
- 仓库: https://github.com/HiDream-ai/HiDream-O1-Image
- 关于自建
/studio路径(Python image_server + Rust handler + Next.js UI)的设计文章将另行发布