Loading...
Kotonia Articles
The real bottleneck was vocabulary, not the layer: unlocking hidden capability in HiDream-O1 via caption vocab repair
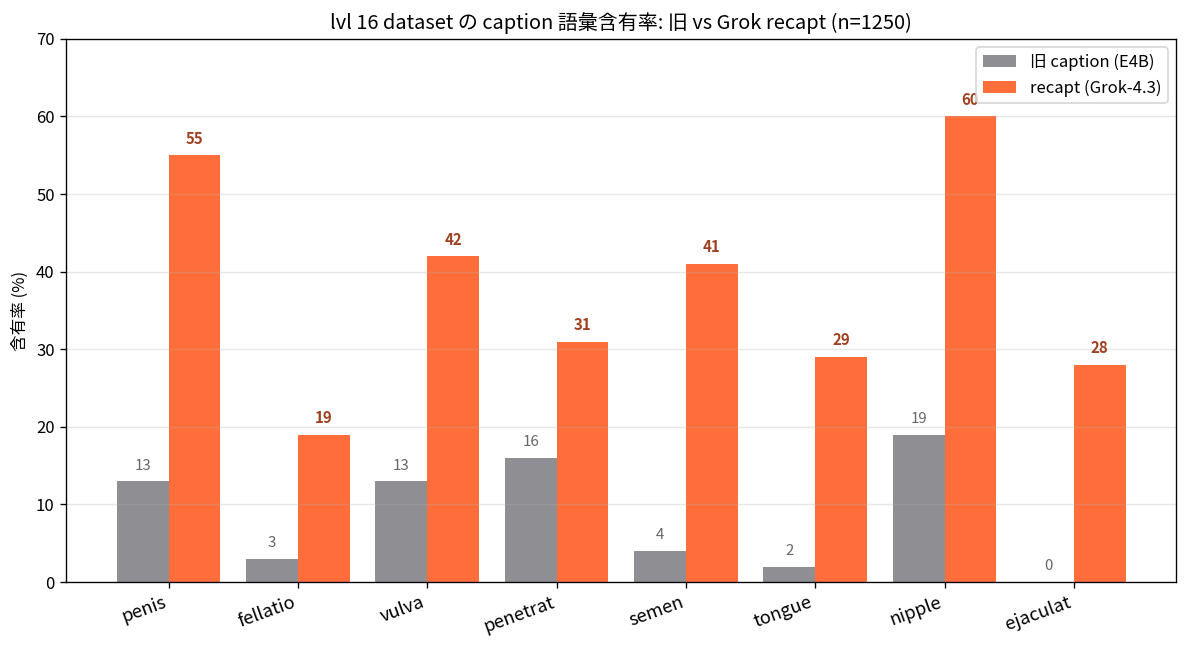
A research note on unlocking NSFW expressivity in HiDream-O1 (8B). The real bottleneck turned out to be the VLM captioner (E4B rounding "fellatio" into "oral sex"), not the model layers. Vocab repair via Grok-4.3 + two-stage prompts, then 8B full fine-tune at 54.6 GB resident on a single 96 GB GPU via bitsandbytes 8-bit Adam. Same-model / different-caption killshot included.
By Shinji Shimizu15 min read
#HiDream-O1#fine-tuning#captioning#NSFW research#OpenWeight