Loading...
Kotonia Articles
真因は層じゃなく語彙だった: HiDream-O1 の隠れた表現力を語彙修復で解禁する
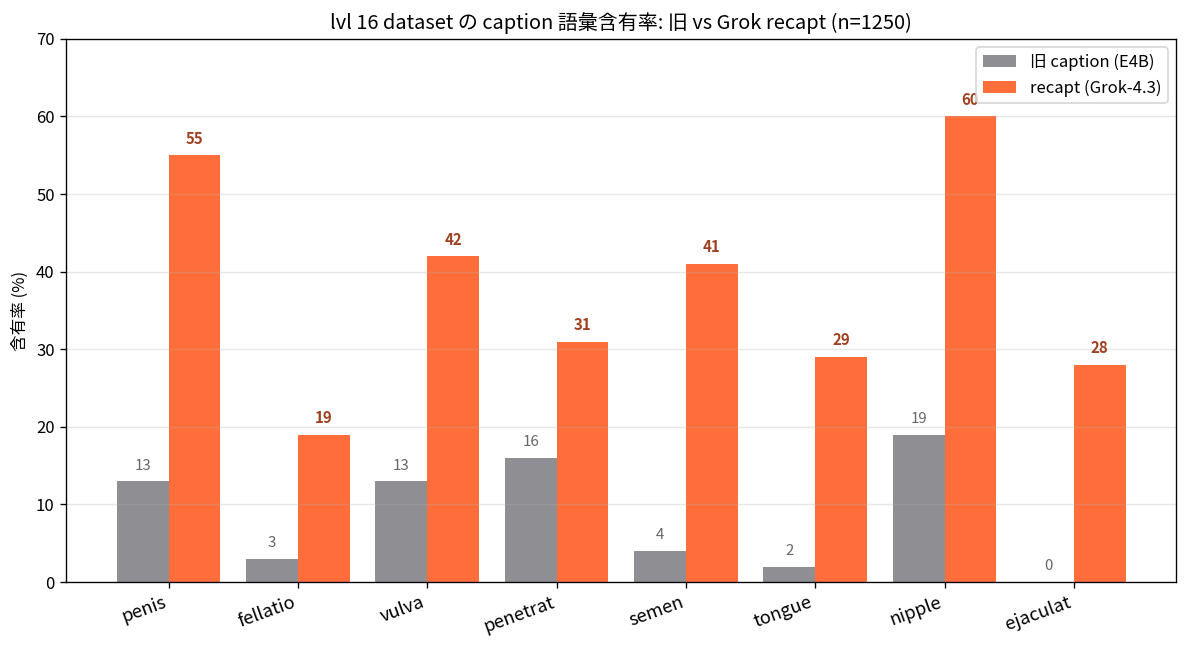
HiDream-O1 (8B) の NSFW 表現力を解禁する過程で、真因が VLM キャプション生成器の言い換え (E4B が "fellatio" を "oral sex" に丸める) だったことを実証。Grok-4.3 + 2 段階プロンプトで語彙修復し、bitsandbytes 8-bit Adam で 96 GB GPU 単体で 8B 全層ファインチューン。同モデル + 異キャプションで描画の有無が分離する決定打を含む研究記録。
著者 清水真二10分で読める
#HiDream-O1#fine-tuning#captioning#NSFW research#OpenWeight