Loading...
Kotonia Articles
真正的瓶颈不在层而在词汇: 用字幕词汇修复解锁 HiDream-O1 的隐藏表达力
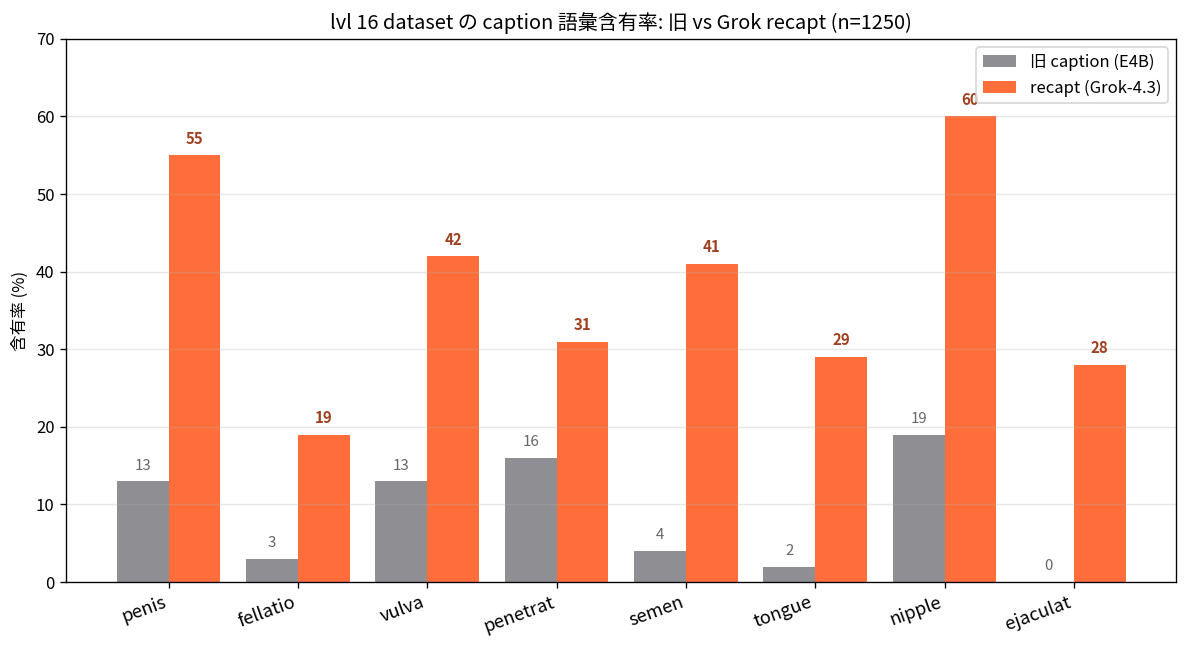
为 HiDream-O1 (8B) 做 NSFW 表达力专项的研究记录。真因不在模型层而在 VLM 字幕器把 "fellatio" 圆滑成 "oral sex"。用 Grok-4.3 + 两段式提示做词汇修复后, 借 bitsandbytes 8-bit Adam 在单张 96 GB GPU 上常驻 54.6 GB 完成 8B 全参微调。包含同模型 / 不同字幕的关键一击。
作者 清水真二8分钟阅读
#HiDream-O1#微调#字幕#NSFW 研究#OpenWeight